
Docker
一、环境搭建(Ubuntu 18.04)
本文前期Docker环境为:Windows10 1809 企业版 + VMware Workstation 15 Pro + Ubuntu 18.04.2LTS
后期Kubernetes环境为:Windows10 1809 企业版 + Vagrant 2.2.7 + VirtualBox 6.1.4 + centos7/Ubuntu 18.04 LTS
Vagrant+VirtualBox
下载Vagrant安装包:官网链接
下载VirtualBox安装包:官网链接,不过VirtualBox下载需要梯子,可以通过清华镜像下载
vagrant的相关image可以通过该网址进行搜索
上述两个软件均傻瓜式安装即可,可以通过下面的方法利用Vagrant在VirtualBox中创建虚拟机:
1 | #查看Vagrant版本 |
- 注意:如需换成其他镜像需要自己去清华镜像(有可能没有)中查找对应的
box文件 - 也可以采取用其他方式下载
box文件(如百度网盘),再通过命令行添加,详细方法即相关地址可以参考这篇博客 - 如果Windows用户名是中文,则可能在
vagrant up这一步报incompatible character encodings: GBK and UTF-8 (Encoding::CompatibilityError)类似错误,具体方法详见这篇博客,概括为以下几步:- 设置环境变量VAGRANT_HOME为不包含中文的路径,该环境变量是用于保存Vagrant下载的
box镜像文件(具体路径为$(VAGRANT_HOME)/.vagrant.d) - 修改VirtualBox中全局配置选项中的 默认虚拟电脑位置VirtualBox VMs的路径 ,不能包含中文名
- 设置环境变量VAGRANT_HOME为不包含中文的路径,该环境变量是用于保存Vagrant下载的
- 注意Vagrant和VirtualBox版本需要匹配,有的版本不匹配可能会报各种错误,本文中测试一切正常
- 默认Vagrant当前配置为在启用
SharedFoldersEnableSymlinksCreate选项的情况下创建VirtualBox同步的文件夹。 如果不信任Vagrant访客,则可能要禁用此选项。 有关此选项的更多信息,请参考VirtualBox手册。- 可以通过环境变量全局禁用此选项:
VAGRANT_DISABLE_VBOXSYMLINKCREATE = 1 - 在Vagrantfile中配置如下代码:
config.vm.synced_folder '/host/path', '/guest/path', SharedFoldersEnableSymlinksCreate: false
- 可以通过环境变量全局禁用此选项:
通过Vagrant命令进入centos7中的shell:
1 | vagrant ssh |
如果想通过其他方式登录虚拟机(如:Xshell),可以通过如下命令获取hostname、port、IdentityFile三个配置信息:
1 | E:\Ubuntu>vagrant ssh-config |
其中:HostName为主机IP地址,Port为开放的端口,IdentityFile为Public Key秘钥文件的路径,依次填入其他软件的相应设置中即可访问该虚拟机
另外,该虚拟机默认登录账号用户名为vagrant,密码为vagrant,root账号密码为vagrant。也有可能没有root密码,需要通过sudo passwd命令重设密码
附:ubuntu18.04换清华源:
编辑
/etc/apt/sources.list文件,修改为以下内容
2
3
4
5
6
7
8
9
10
11
12
13
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
安装Docker Engine - Community
官方文档教程详见:Install Docker Engine on Ubuntu | Docker Documentation
设置源
1 | #如果有之前的版本 需要删除 |
由于Docker hub源不稳定,推荐国内源:
- docker官方中国区
https://registry.docker-cn.com- 网易
http://hub-mirror.c.163.com- ustc
http://docker.mirrors.ustc.edu.cn
- 2020 年 4 月起失效
- 阿里云
http://<你的ID>.mirror.aliyuncs.comustc帮助文档:https://lug.ustc.edu.cn/wiki/mirrors/help/docker
2
3
4
5
6
7
8
#添加以下内容 注意不能是https 否则最后一点下载不下来
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn/","https://hub-mirror.c.163.com","https://registry.docker-cn.com"],
......
}
#重启docker服务
service docker restart
- 可以通过
docker info查看是否设置成功
安装
1 | #安装Docker Engine - Community |
或者自己选择版本安装
2
3
sudo apt-get install docker-ce=<VERSION_STRING> docker-ce-cli=<VERSION_STRING> containerd.io
卸载Docker Engine - Community
1 | sudo apt-get purge docker-ce |
nvidia docker
NVIDIA于2016年开始设计NVIDIA-Docker以便于容器使用NVIDIA GPUs。 第一代nvidia-docker1.0实现了对docker client的封装,并在容器启动时,将必要的GPU device和libraries挂载到容器中。但是这种设计的方式高度的与docker运行时耦合,缺乏灵活性:
- 设计高度与docker耦合,不支持其它的容器运行时。如: LXC, CRI-O及未来可能会增加的容器运行时。
- 不能更好的利用docker生态的其它工具。如: docker compose。
- 不能将GPU作为调度系统的一种资源来进行灵活的调度。
- 完善容器运行时对GPU的支持。如: 自动的获取用户层面的NVIDIA Driver libraries, NVIDIA kernel modules, device ordering等。
基于上面描述的这些弊端,NVIDIA开始了对下一代容器运行时的设计: nvidia-docker2.0
nvidia-docker2.0中核心部分是nvidia-container-runtime,在原有的docker容器运行时runc的基础上增加一个prestart hook,用于调用libnvidia-container库
RunC 是一个轻量级的工具,用来运行容器。可以认为它是个命令行小工具,可以不用通过 docker 引擎,直接运行容器。
事实上,runC 是标准化的产物,它根据 OCI 标准来创建和运行容器。而 OCI(Open Container Initiative)组织,旨在围绕容器格式和运行时制定一个开放的工业化标准。
直接使用RunC的命令行即可以完成创建一个容器,并提供了简单的交互能力。
正常创建容器流程:docker --> dockerd --> containerd--> containerd-shim -->runc --> container-process
创建gpu容器:docker--> dockerd --> containerd --> containerd-shim--> nvidia-container-runtime --> nvidia-container-runtime-hook --> libnvidia-container --> runc -- > container-process
安装
参考链接:
- 项目源码:NVIDIA/nvidia-docker: Build and run Docker containers leveraging NVIDIA GPUs
- 官方安装指南:Installation Guide — NVIDIA Cloud Native Technologies documentation
- 官方使用手册:User Guide — NVIDIA Cloud Native Technologies documentation
- docker hub镜像:nvidia/cuda - Docker Image
- 官方FAQ:NVIDIA/nvidia-docker Wiki
配置要求:
- Linux内核版本 > 3.10
- Docker版本 >= 19.03
- NVIDIA GPU架构最低需求 >= Kepler
- NVIDIA Linux 驱动 >= 418.81.07
根据上述章节安装完docker后即可安装nvidia docker。nvidia docker分为两个版本,推荐安装nvidia docker2
1 | #添加nvidia官方GPG秘钥 |
- 这里在Ubuntu20.04上最后安装的源是用的18.04的,可能是官方还未修改
1 | # 安装nvidia docker2 |
- 如果在之前换过docker hub源,这里在安装nvidia docker2是会报一个警告,直接按y同意替换即可,之后再手动将源修改回来
1 | # 重启并验证nvidia docker2 |
- nvidia docker提供三种类型的镜像:
- base:包括cuda(cudart)
- runtime:base+cuda数学库+NCCL+cuDNN
- devel:runtime+各种cuda头文件+cuda开发工具包
环境变量设置
可以通过设置特定的环境变量或者CLI中传入特定参数使用
gpu数量
用户能够通过系统环境变量NVIDIA_VISIBLE_DEVICES或者docker CLI的--gpu选项指定gpu:
| 变量值 | 描述 |
|---|---|
0,1,2, 或 GPU-fef8089b |
GPU UUID 或索引列表 |
all |
所有gpu均可用,默认值 |
none |
所有gpu均不可用,但是驱动仍正常使用 |
void or empty or unset |
nvidia-container-runtime 将与 runc行为一样 (如:没有gpu也没有驱动) |
- 使用环境变量时,需要添加
--runtime=nvidia参数,否则将使用默认参数
1 | # 使用--gpus参数 |
驱动
设置环境变量NVIDIA_DRIVER_CAPABILITIES,或--gpus参数即可:
| 变量值 | 描述值 |
|---|---|
compute,video 或 graphics,utility |
容器需要的驱动程序功能的逗号分隔列表 |
all |
使能全部功能 |
| empty or unset | 默认utility |
下面提供了支持的驱动程序功能:
| 驱动参数 | 描述 |
|---|---|
compute |
CUDA + OpenCL |
compat32 |
32位程序 |
graphics |
OpenGL + Vulkan |
utility |
nvidia-smi 和 NVML |
video |
Video Codec SDK |
display |
X11 |
1 | # 需要CUDA 和 NVML 能力 |
资源限制
通过如下的一个逻辑表达式,定义容器上软件版本或 GPU 架构的约束。
基本形式为NVIDIA_REQUIRE_*,支持以下几种:
| 约束 | 描述 |
|---|---|
cuda |
限制CUDA版本 |
driver |
限制驱动版本 |
arch |
限制gpu的架构 |
brand |
限制gpu的型号(如:GeForce, Tesla, GRID) |
1 | # 限制驱动与cuda版本 |
NVIDIA_DISABLE_REQUIRE宏则会禁用上述限制
二、Docker的镜像和容器
架构和底层
- Docker是一个平台,提供一个开发、打包、运行app的平台
- 把app和底层设备隔离开
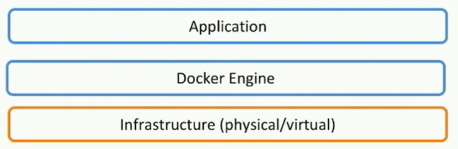
Docker Engine:
- 后台进程(dockerd)
- 提供 REST API 的服务(Server)
- 提供 CLI(client,客户端)
- C-S架构
- 提供 REST API 的服务(Server)
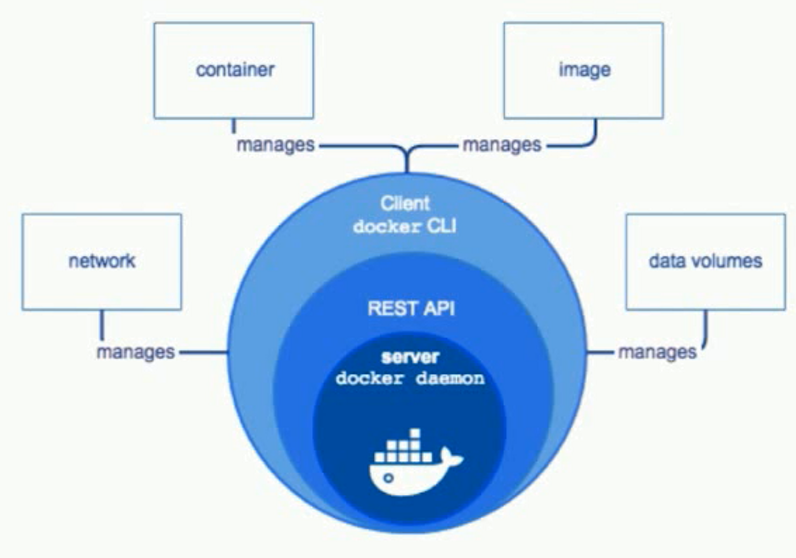
整体架构:
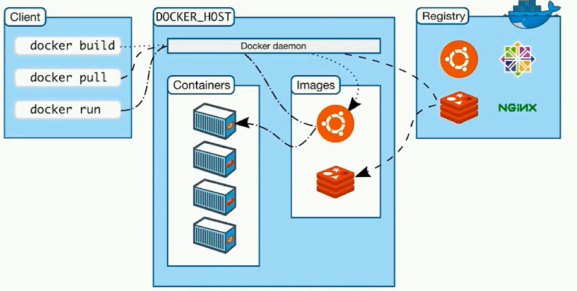
- Client:Docker提供的命令(可以和host在一台机器上)
- Docker Host:启动了dockerd的机器
- images
- containers
- Registry:库,类似于GitHub
docker底层技术支持:
- Namespaces:隔离pid、net、ipc、mnt、uts
- Control groups:做资源限制
- Union file systems:Container和 nimage的分层
Image
官方命令手册:https://docs.docker.com/engine/reference/commandline/image/
- 文件和 meta data的集合( root filesystem)
- 分层的,并且每一层都可以添加改变删除文件,成为一个新的image
- 不同的image可以共享相同的 layer
- Image本身是read-only的
Dockerfile:通过该文件定义一个image并能够构建该image
BaseImge:直接基于Linux的内核,在内核上制作的一个镜像(如各种Linux的发行版:ubuntu、centos等),可以在该镜像上在制作一个新的image
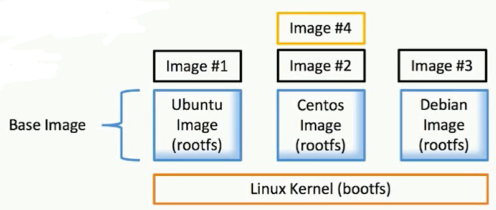
Container
官方命令手册:https://docs.docker.com/engine/reference/commandline/container/
- 通过image创建(copy)
- 在image layer之上建立一个container layer(可读写)
- 类比面向对象:类(image)和实例(container)
- Image负责app的存储和分发, Container负责运行app
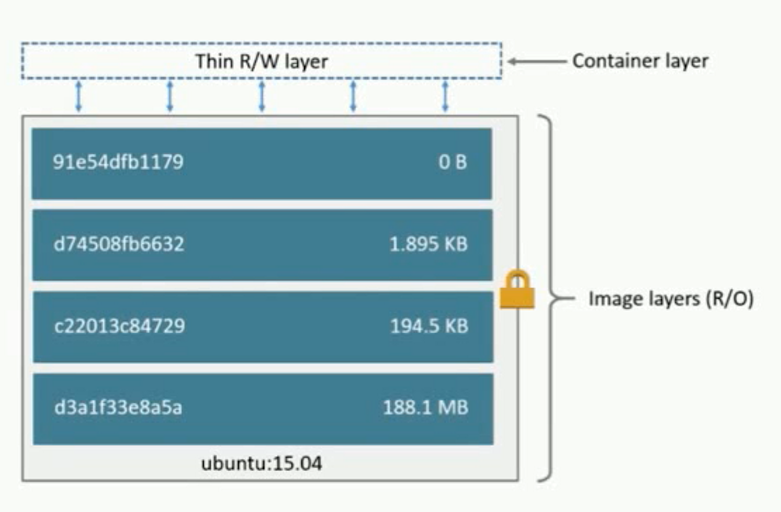
构建自己的image
1 | #基于container(xxx,名字,name)创建一个image(yyy) 不提倡,不安全 |
调试
每次构建的时候,在每一层都会生成临时容器并通过-->显示出该容器的id(docker images也可以,注意观察生成时间),可以通过
1 | sudo docker run -it 临时容器id /bin/bash |
有时候会因为升级docker镜像中的软件失败而导致镜像生成失败,此时通过进入docker内部更换清华源即可
运行
1 | sudo docker run image名字 |
--name指定的名字具有唯一性,可以替代id用于别的命令docker start:只要不删除,该命令就能够重新启动stop的容器
exec:进运行中的容器内部,看具体的细节
1 | sudo docker exec -it 容器id /bin/bash#exec:对运行中的容器执行的命令(/bin/bash) -it:交互式的执行 |
- 不止运行/bin/bash,还可运行其他命令,如:python等
DockerFile
官方文档:https://docs.docker.com/develop/develop-images/dockerfile_best-practices/
-
FROM:选择base image,在该base image上构建新的imageFROM scratch:从头制作base image- 尽量使用官方的image作为 base image
-
LABEL:定义image的metadata(类似代码中的注释)-
LABEL maintainer="xiaoquwl@gmail.com" LABEL version="1.0" LABEL description="This is description"1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
* 不可少,能够让人更加明白
* `RUN`:运行命令,每一次RUN都会使image生成新的一层
* 为了美观,复杂的RUN请用反斜线换行
* 避免无用分层,合并多条命令成一行
* ```dockerfile
RUN yum update && yum install -y vim \
python-dev#反斜线换行
RUN apt-get update && apt-get install -y perl \
pwgen --no-install-recommends && rm -rf \
/var/ib/apt/ists/*#注意清理 cache
RUN /bin/bash -c 'source $HOME/.bashrc; echo $HOME'
-
-
WORKDIR:设定当前工作目录(类似于cd)-
WORKDIR /test#如果没有会自动创建test目录 WORKDIR demo RUN pwd#输出结果应该是/test/demo1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
* 用 `WORKDIR`,不要用 `RUN cd`
* 尽量使用绝对目录
* `ADD`和`COPY`:把本地的一些文件添加到docker image中
* ADD除了拷贝的功能外还能够解压缩
* 大部分情况,COPY优于ADD
* 添加远程文件/目录请使用curl或者wget
* ```dockerfile
ADd hello /#简单拷贝
ADD test.tar.gz /#添加到根目录并解压
#WORKDIR和ADD联合使用
WORKDIR /root
ADD hello test/ #hello文件位置/root/test/hello
WORKDIR /root
COPY hello test/ #hello文件位置/root/test/hello
-
-
ENV:设置一个环境变量或常量-
尽量使用ENV增加可维护性
-
ENV MYSQL_VERSION 5.6#设置常量 RUN apt-get install -y mysql-server="${MYSQL_VERSION}" \ && rm -rf /var/lib/apt/lists/*#引用常量1
2
3
4
5
6
7
8
9
10
11
12
13
14
* `VOLUME`和`EXPOSE`:主要用于存储和网络
* `VOLUME`:指定在容器中某一个目录中产生的数据,同时挂载到Linux主机中的某一个目录上,并且会创建一个docker volume的对象
* `EXPOSE`:会将运行中的container中的端口暴露出来
* shell和exec格式
* shell格式:后面是shell命令
* ```dockerfile
RUN apt-get install -y vim
CMD echo "hello docker"
ENTRYPOINT echo "hello docker" -
exec格式:需要根据特点的格式指出命令和参数
-
#XXX ["命令","参数",...] RUN ["apt-get","install","-y","vim"] CMD ["/bin/echo","hello docker"] ENTRYPOINT ["/bin/echo","hello docker"] #以下两种输出结果不一样 ENV name Docker ENTRYPOINT ["/bin/echo","hello $name"]#hello $name ENTRYPOINT ["/bin/bash","-c","echo hello $name"]#hello Docker(-c表示后面的事bash的参数)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
* `CMD`和`ENTRYPOINT`:
* `RUN`:执行命令并创建新的 image Layer
* `CMD`:设置容器启动后默认执行的命令和参数
* 容器启动时默认执行的命令
* 如果 docker run指定了其它命令,CMD命令被忽略
* 此处docker run指`docker run 镜像名`,再加任意一个参数均会忽略CMD命令,如`docker run -it 镜像名 /bin/bash`
* 如果定义了多个CMD,只有最后一个会执行
* `ENTRYPOINT`:设置容器启动时运行的命令
* 让容器以应用程序或者服务的形式运行
* 不会被忽略,一定会执行
* ```dockerfile
#执行一个shel脚本
COPY docker-entrypoint.sh /usr/local/bin/
ENTRYPOINT ["docker-entrypoint sh"]
-
-
发布镜像
直接发布镜像:
-
在DockerHub网站上注册账号
-
sudo docker login,在本机上通过命令行登录DockerHub -
sudo docker push 账号名/image名字:tag或sudo push 账号名/image名字:tag往DockerHub上推
发布Dockerfile:
- 在DockerHub上绑定Github账号
- 在GitHub上分享Dockerfile
- DockerHub会自动从GitHub上克隆Dockerfile
- DockerHub后台服务器会自动根据Dockerfile构建image
容器资源限制
不做限制的容器会尽最大可能占用物理机的资源,可以通过docker run命令指定对容器的限制
- 对memory的限制
--memory:若只指定该参数,则swap memory也是同样大小,总共消耗内存为2*memory- eg:sudo docker run --memory=200M 容器id
--memory-swap:指定swap memory参数
- 对cpu的限制
--cpu-shares:限制相对权重,即每个容器根据该值来分配物理机上的cpu算力- sudo docker run --cpu-shares=10 --name=test1 容器id --cpu 1
- sudo docker run --cpu-shares=5 --name=test2 容器id --cpu 1
- 上述两个容器会按照test1:test2=2:1占用cpu
--cpu:利用编号指定运行的cpu
实战——ubuntu上打包stress
python常驻程序
新建Dockerfile:
1 | FROM python:2.7 |
EXPOSE:在此处代表要暴露出去的端口CMD:此处用于表示之后一直运行的程序
ubuntu上打包stress
新建Dockerfile:
1 | FROM ubuntu |
ENTRYPOINT:在此处代表要执行的命令CMD:此处用于接受之后docker run后的参数,传递给ENTRYPOINT指定的命令- 可以在
[]中指定默认的参数
- 可以在
常用命令
全部命令详见官方文档
1 | #使docker前不需要加sudo |
生命周期管理
run
创建一个新的容器并运行一个命令
1 | docker run [OPTIONS] IMAGE [COMMAND] [ARG...] |
COMMAND和ARG为在起来的容器中执行的命令与参数
OPTIONS:
-d:后台运行,并返回容器ID-e:设置环境变量--env-file=[]:从指定文件读入环境变量
-it:交互运行,并进入其shell-i:以交互模式运行容器-t:为容器重新分配一个伪输入终端
--name:为容器指定一个名称(设置别名)- 网络参数
--net="bridge":指定容器的网络连接类型,支持 bridge/host/none/container: 四种类型,详见 [三、docker网络](# 三、docker网络)--link=[]:添加链接到另一个容器,详见 [docker之间的link](# docker之间的link)-p:端口映射,格式为:主机(宿主)端口:容器端口,详见 [端口映射](# 端口映射)--expose=[]:开放一个端口或一组端口;--dns 8.8.8.8:指定容器使用的DNS服务器,默认和宿主一致--dns-search example.com:指定容器DNS搜索域名,默认和宿主一致;-h "mars":指定容器的hostname;
- 资源参数
--volume,-v:绑定一个卷,详见 [四、Docker的持久化存储和数据共享](# 四、Docker的持久化存储和数据共享)--cpuset="0-2",--cpuset="0,1,2":绑定容器到指定CPU运行-m:设置容器使用内存最大值
start/stop/restart
启动、停止、重启容器
1 | docker start [OPTIONS] CONTAINER [CONTAINER...] |
kill
杀掉一个运行中的容器
1 | docker kill [OPTIONS] CONTAINER [CONTAINER...] |
-s:向容器发送一个信号
rm
删除一个或多个容器
1 | docker rm [OPTIONS] CONTAINER [CONTAINER...] |
-f:通过SIGKILL信号强制删除一个运行中的容器-l:同时移除容器间的网络连接,而非容器本身(不加CONTAINER则只删除连接)-v:同时删除与容器关联的卷(不加CONTAINER则只删除卷)
pause/unpause
暂停/恢复容器中所有的进程
1 | docker pause CONTAINER [CONTAINER...] |
create
创建一个新的容器但不启动它(用法同[docker run](# run))
1 | docker create [OPTIONS] IMAGE [COMMAND] [ARG...] |
exec
在运行的容器中执行命令
1 | docker exec [OPTIONS] CONTAINER COMMAND [ARG...] |
-d:后台运行,并返回容器ID-it:交互运行,并进入其shell-i:以交互模式运行容器-t:为容器重新分配一个伪输入终端
容器操作
以下操作全都是docker container打头,可以省略container。一般来说容器有以下几种状态:
- created(已创建)
- restarting(重启中)
- running(运行中)
- removing(迁移中)
- paused(暂停)
- exited(停止)
- dead(死亡)
ps
列出所有在运行的容器信息
1 | docker ps [OPTIONS] |
-
-aq:列出所有创建的容器ID-a:显示所有的容器,包括未运行的-q:静默模式,只显示容器编号
-
-f,--filter:根据条件过滤显示的内容-
# 根据名称过滤 docker ps --filter "name=test-nginx"1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
* `-l`:显示最近创建的容器
* `-n`:列出最近创建的n个容器
* `--no-trunc`:不截断输出(防止信息显示不全)
* `-s`:显示该容器占用的大小
##### inspect
获取容器/镜像的元数据(即配置时的`.yml`文件)
```bash
docker inspect [OPTIONS] NAME|ID [NAME|ID...]
-
-
-f:指定返回值的Go模板文件,该模板有相关的语法,具体可以参考docker inspect -f 模版1
2
3
4
5# 查看所有容器(包括未运行)的容器状态
docker inspect -f '{{.State.Status}}' $(docker ps -aq)
docker inspect --format='{{.State.Status}}' $(docker ps -aq)
# 可以通过级联调用直接读取子对象 State 的 Status 属性,以获取容器的状态信息:
docker inspect --format '{{/*读取容器状态*/}}{{.State.Status}}' $INSTANCE_ID- 大括号内处理模版指令,大括号外的任何字符都将直接输出
.:当前上下文- 可以使用
$来获取根上下文
top
查看容器中运行的进程信息,支持 ps 命令参数。主要用于容器内没有shell或top命令的
1 | docker top [OPTIONS] CONTAINER [ps OPTIONS] |
attach
连接到正在运行中的容器,可以同时连接一个容器来共享shell输出
1 | docker attach [OPTIONS] CONTAINER |
--sig-proxy=false:确保CTRL-D或CTRL-C不会关闭容器,仅仅用作退出该连接(即detach)
events
从服务器获取实时事件
1 | docker events [OPTIONS] |
-f:根据条件过滤事件- 时间设置(如果指定的时间是到秒级的,需要将时间转成时间戳。如果时间为日期的话,可以直接使用,如
--since="2016-07-01")--since:从指定的时间戳后显示所有事件--until:流水时间显示到指定的时间为止
logs
获取容器的日志
1 | docker logs [OPTIONS] CONTAINER |
-f:跟踪日志输出--tail:仅列出最新N条容器日志-t:显示时间戳--since:显示某个开始时间的所有日志
wait
阻塞运行直到容器停止,然后打印出它的退出代码
1 | docker wait [OPTIONS] CONTAINER [CONTAINER...] |
export
将容器的文件系统作为一个tar归档文件导出,主要用来制作基础镜像(导入命令[docker import](# import))
1 | docker export [OPTIONS] CONTAINER |
-o:设置导出的文件
port
列出指定的容器的端口映射情况
1 | docker port [OPTIONS] CONTAINER [PRIVATE_PORT[/PROTO]] |
images管理
images
列出本地镜像
1 | docker images [OPTIONS] [REPOSITORY[:TAG]] |
-a:列出本地所有的镜像(含中间映像层,默认情况下会过滤掉中间映像层)--digests:显示镜像的摘要信息-f:显示满足条件的镜像--format:指定返回值的模板文件--no-trunc:显示完整的镜像信息(防止信息显示不全)-q:静默模式,只显示镜像ID
rmi
删除本地一个或多少镜像
1 | docker rmi [OPTIONS] IMAGE [IMAGE...] |
-f:强制删除
tag
标记本地镜像,将其归入某一仓库
1 | docker tag [OPTIONS] IMAGE[:TAG] [REGISTRYHOST/][USERNAME/]NAME[:TAG] |
build
通过 Dockerfile 创建镜像
1 | docker build [OPTIONS] PATH | URL | - |
- 资源限制
--cpu-shares:设置 cpu 使用权重--cpuset-cpus:指定使用的CPU id-m:设置内存最大值--memory-swap:设置swap的最大值,"-1"表示不限swap
--disable-content-trust:忽略校验,默认开启-f:指定要使用的Dockerfile路径,默认为当前目录--force-rm,--rm:设置镜像过程中删除中间容器--quiet,-q:安静模式,成功后只输出镜像 ID--squash:将 Dockerfile 中所有的操作压缩为一层--tag,-t:镜像的名字及标签,通常 name:tag 或者 name 格式;可以在一次构建中为一个镜像设置多个标签
例子:
1 | # 使用当前目录的 Dockerfile 创建镜像,标签为 runoob/ubuntu:v1 |
history
查看指定镜像的创建历史
1 | docker history [OPTIONS] IMAGE |
--no-trunc:显示完整的提交记录(防止信息显示不全)-q:安静模式,仅列出提交记录ID
save
将指定镜像保存成 tar 归档文件(导入命令[docker load](# load))
1 | docker save [OPTIONS] IMAGE [IMAGE...] |
-o:设置导出的文件
load
导入使用 [docker save](# save) 命令导出的镜像
1 | docker load [OPTIONS] |
-
--input,-i:指定导入的文件,代替 STDIN(默认为标准输入)1
2docker load < busybox.tar.gz
docker load --input fedora.tar -
--quiet,-q:精简输出信息
import
从 [docker export](# export) 创建的归档文件中创建镜像
1 | docker import [OPTIONS] file|URL|- [REPOSITORY[:TAG]] |
-c:应用 [docker export](# export) 指令创建镜像(默认为标准输入)-m:提交时的说明文字
导入导出汇总
一般来说,分为以下两种,不能混用:
- 导入/导出image:[docker save](# save)、[docker load](# load)
- 保存完整记录,但是体积较大
- 导入/导出快照:[docker export](# export)、[docker import](# import)
- 没有 layer 信息,dockerfile 里的 workdir,entrypoint 之类的所有东西都会丢失,commit 也会丢失。即丢弃所有的历史记录和元数据信息(即仅保存容器当时的快照状态),体积较小
其区别如下:
- [docker save](# save) 保存的是镜像(image),[docker export](# export) 保存的是容器(container);
- [docker load](# load) 用来载入镜像包,[docker import](# import) 用来载入容器包,但两者都会恢复为镜像;
- [docker load](# load) 不能对载入的镜像重命名,而 [docker import](# import) 可以为镜像指定新名称。
仓库管理
login/logout
1 | docker login [OPTIONS] [SERVER] |
-u:登陆的用户名-p:登陆的密码
pull
从镜像仓库中拉取或者更新指定镜像
1 | docker pull [OPTIONS] NAME[:TAG|@DIGEST] |
-a:拉取所有 tagged 镜像
push
将本地的镜像上传到镜像仓库,需要先登陆到镜像仓库
1 | docker push [OPTIONS] NAME[:TAG] |
search
从Docker Hub查找镜像
1 | docker search [OPTIONS] TERM |
-
--automated:只列出自动构建类型的镜像 -
--no-trunc:显示完整的镜像描述 -
-f <过滤条件>:列出收藏数不小于指定值的镜像1
2# 查找所有镜像名包含 java,并且收藏数大于 10 的镜像
docker search -f stars=10 java
容器文件系统管理
commit
从容器创建一个新的镜像
1 | docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]] |
-a:提交的镜像作者-c:使用Dockerfile指令来创建镜像-m:提交时的说明文字-p:在commit时,将容器暂停
cp
容器与主机之间的数据拷贝
1 | docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH |
-L:保持源目标中的链接
diff
检查容器里文件结构的更改
1 | docker diff [OPTIONS] CONTAINER |
三、docker网络
docker网络分类:
- 单机网络
- Bridge Network
- Host Network
- None Network
- 多机网络
- Overlay Network
基本概念
整个网络的数据传输是通过数据包的形式来传输的
数据包的打包有一个分层的概念,即ISO/OSI的七层模型和TCP/IP的五层模型:

数据包到达另一台电脑或服务器,需要通过路由
IP地址:设备的标识
- 公有IP:互联网上的唯一标识,可以访问 Internet
- 私有IP:不可在互联网上使用,仅供机构内部使用
- ABC三类ip地址:https://blog.csdn.net/kzadmxz/article/details/73658168
私有IP地址访问互联网,需要网络地址转换,即NAT
Linux命令:
ping:检查ip的可达性,ping不通不能保证机器出问题了,可能是中间路由或者防火墙等其他某一环节出问题了telnet:检查服务的可用性
Linux中network namespace
每创建一个container,会同时创建一个network namespace
1 | #查看本机network namespace |
其他相关命令和知识可以参考这篇博客,如链接消失,可见我博客中的备份
Docker Bridge0详解
即bridge Network。
建议参考上一小节中提到的博客
1 | #列出当前docker中有哪些网络 |
两个容器之间相互通信的情况:
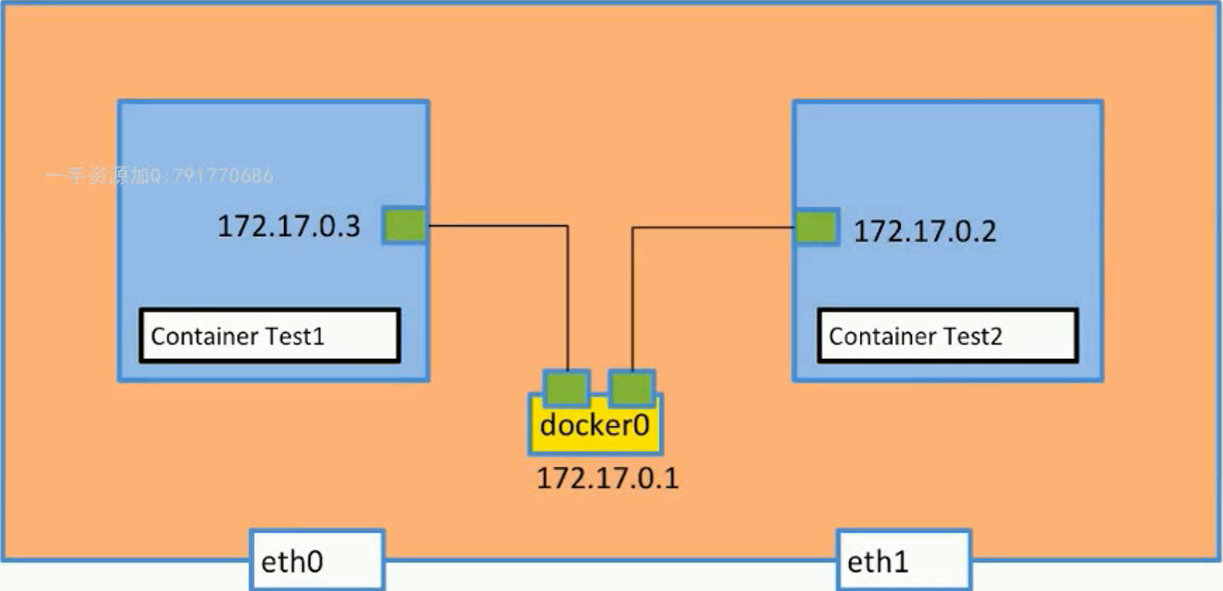
- 蓝色框框为两个容器
- 绿色的一对为veth(虚拟网络接口)
- docker容器中会连接到主机的docker0网卡上
单个容器访问internet的情况:
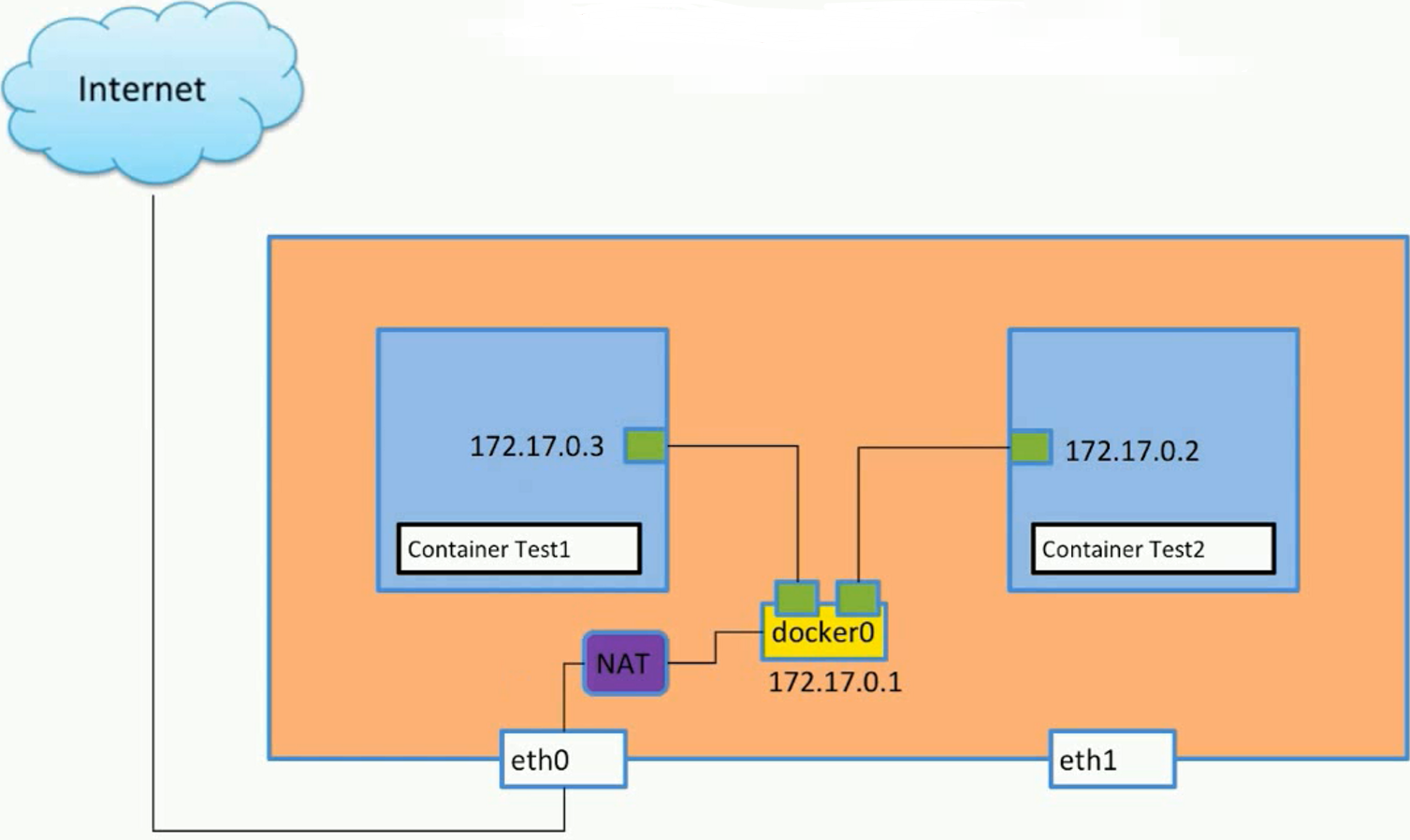
- 主机通过eth0访问外网
- docker0中的数据通过NAT(网络地址转换)转换到eth0中
- 这里的NAT是通过iptables实现
docker之间的link
即通过link指令,可以将一个容器只需指定对方容器名字就可以链接到另一个容器上,而无需指定IP地址及端口。注意,link指令含有方向,只能单向链接
该指令实际使用不多
直接上例子
1 | #创建busybox容器test1 |
创建一个新的Bridge并连接上Container:
1 | #创建一个新的bridge,叫my-bridge(-d:driver) |
多个容器若都连接在了同一个用户自己创建的bridge上,则可以不需通过链接就能够通过名字直接访问
1 | #进入my-bridge绑定的test3中,可以直接通过名字ping通后来接入的test2(ip:192.18.0.3) |
端口映射
如果想要将docker中的端口转发给外部:
1 | #将容器中的80端口映射到本地的80端口 |
示意图:
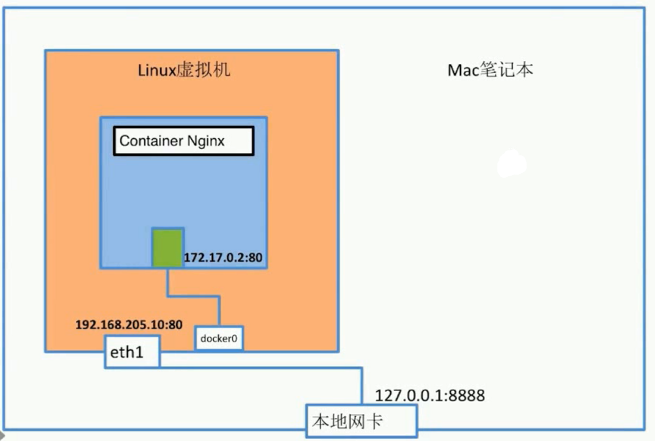
- 注:eth1到本地网卡上的端口转发是通过设置虚拟机修改而成的
host和none网络
none network:
1 | #创建busybox容器test1,指定network为none |
- none network表示一种孤立的网络,除了
sudo docker exec -it命令能够访问之外,不能通过其他方法访问
host network:
1 | #创建busybox容器test1,指定network为host |
- host network表示该容器没有自己独立的namespace,根Linux主机中的namespace network共享同一套
- 可能会和Linux主机上的一些端口存在冲突
多机通信
为实现如下效果:
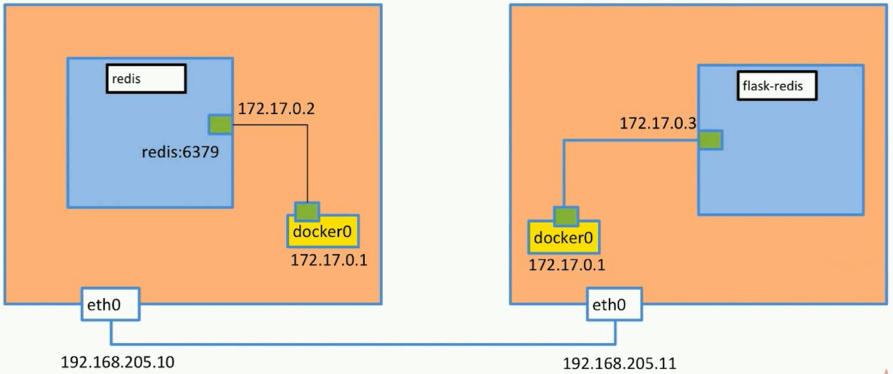
- 两个docker的ip地址需要不一样
- 运用VXLAN技术
- 通过overlay network实现,创建overlay与bridge、host、none一致
- 需要用到分布式存储技术(采用etcd),用于在单机上占据ip地址
四、Docker的持久化存储和数据共享
回顾之前讲的Container,Container具有可读可写的能力,image只具有可读的能力。但是在stop再rm Container之后,Container中的数据不会保存,Container中的数据相当于一个临时的数据
docker持久化数据的方案分以下两种:
- 基于本地文件系统的 Volume.可以在执行 Docker create或 Docker run时,通过
-v参数将主机的目录作为容器的数据卷.这部分功能便是基于本地文件系统的 volume管理. - 基于plugin的 Volume,支持第三方的存储方案,比如NAS,aws
Volume的类型:
- 受管理的 data Volume,由 docker后台自动创建.
- 绑定挂载的 Volume,具体挂载位置可以由用户指定.
Data Volume
场景:一般来说有些容器自己会产生一些数据,我们需要保证这些数据的安全,不想随着container的消失而消失,比如说数据库等,通过Dockerfile中的VOLUME关键字实现。
1 | #创建mysql container(mysql的Dockerfile中有:VOLUME /var/lib/mysql),初始密码为空,将在/var/lib/mysql处产生的volume重命名为mysql(将mysql volume映射到container中的/var/lib/mysql目录) |
Bind Mounting(挂载宿主机目录)
bind Mounting不需要在Dockerfile中定义文件产生的路径,只需在命令行中指定即可:
1 | #创建容器,将当前目录$(pwd)映射到container中的/usr/share/nginx/html目录 |
五、Docker Compose多容器部署
官方链接:https://docs.docker.com/compose/、https://docs.docker.com/compose/compose-file/
多容器的app会带来的缺点:
- 要从 Dockerfile build image或者 Dockerhub拉取 image
- 要创建多个 container
- 要管理这些 container(启动、停止、删除)
Docker Compose的诞生就是为了解决该问题,可以看成是批处理
- Docker Compose是一个命令行工具
- 这个工具可以通过一个
yml文件定义多容器的 docker应用 - 通过一条命令就可以根据
yml文件的定义去创建或者管理这多个容器
yml文件默认名:docker-compose.yml,包含三个重要概念:Services、Networks、Volumes
Services:
-
一个 service代表一个 container,这个 container可以从dockerhub的image来创建,或者从本地的 Dockerfile build出来的image来创建
-
Service的启动类似 docker run,我们可以给其指定network和 volume,所以可以给 service指定 network和Volume的引用(service中的参数和docker run中的参数类似)
1
2
3
4
5
6
7services:
db:#services名字
image:postgres:9.4#采用的image
volumes:
- “db-data:/var/lib/postgresql/data”
network:#新建的bridge
- back-tier1
2
3
4
5
6
7
8services:
worker:
build:./worker
links:#有了network,links可有可无
- db
- redis
network:
- back-tier
实例:
1 | version: '3' |
安装和基本使用
安装:
-
docker for mac或windows 会自动安装
-
Linux安装步骤:https://docs.docker.com/compose/install/
1
2
3
4
5
6#下载至/usr/local/bin/docker-compose
sudo curl -L "https://github.com/docker/compose/releases/download/1.25.3/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
#添加可执行权限
sudo chmod +x /usr/local/bin/docker-compose
#查看版本信息 验证是否安装成功
docker-compose --version
使用:
docker Compose的使用大部分都会联合yml文件的使用
1 | #创建docker-compose.yml文件中的service |
水平扩展和负载均衡
通过docker-compose命令的--scale参数
1 | #多开service中的container |
六、容器编排Swarm mode
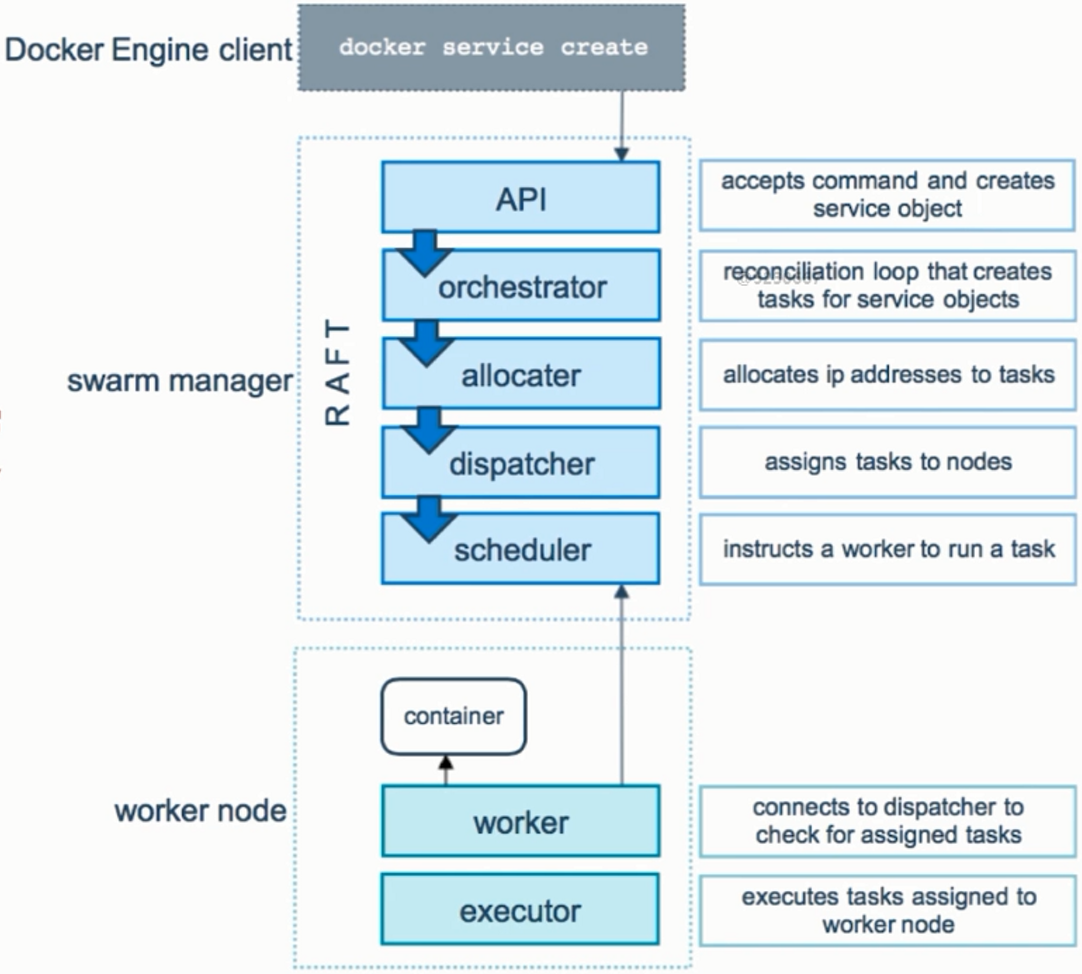
Swarm是一种集群的架构,其中含有节点,每一个节点中可以含有两种角色,即manager和worker
- manager:整个集群的大脑,至少需要2个及以上,所以需要同步,docker提供了一个内置的分布式的存储数据库,通过raft协议进行同步
- worker:节点比manager多,通过gossip网络进行同步
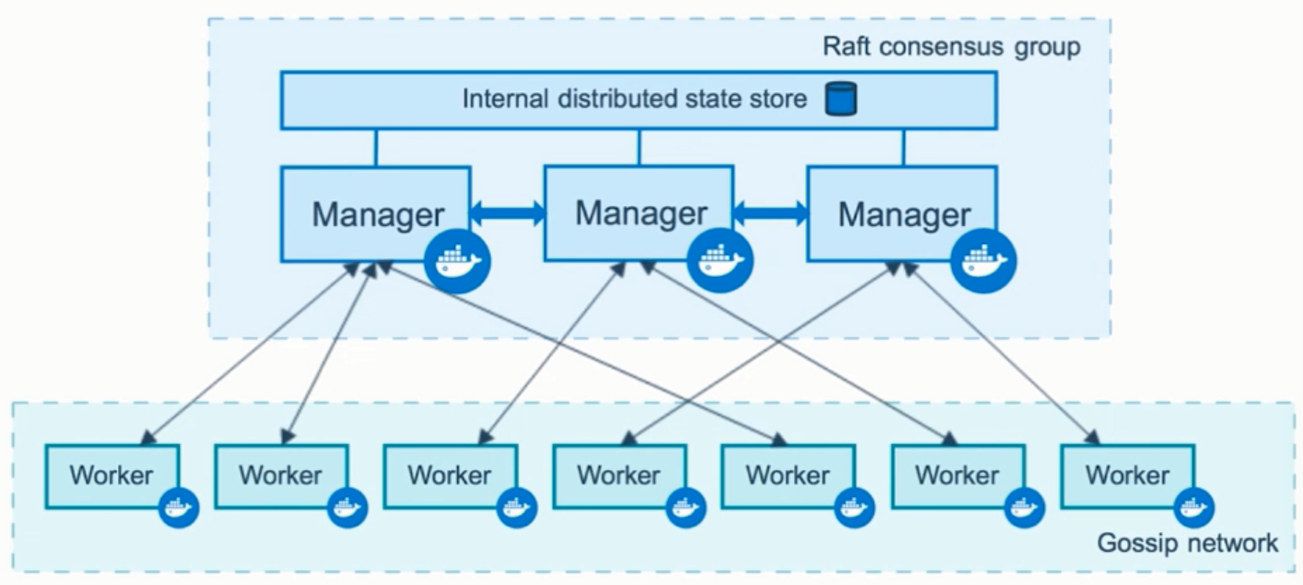
重要概念:
- Service:与docker Compose中的service类似,但是最终运行在那台机器上是不确定的
- Replicas:横向扩展时,一个replicas就是一个容器
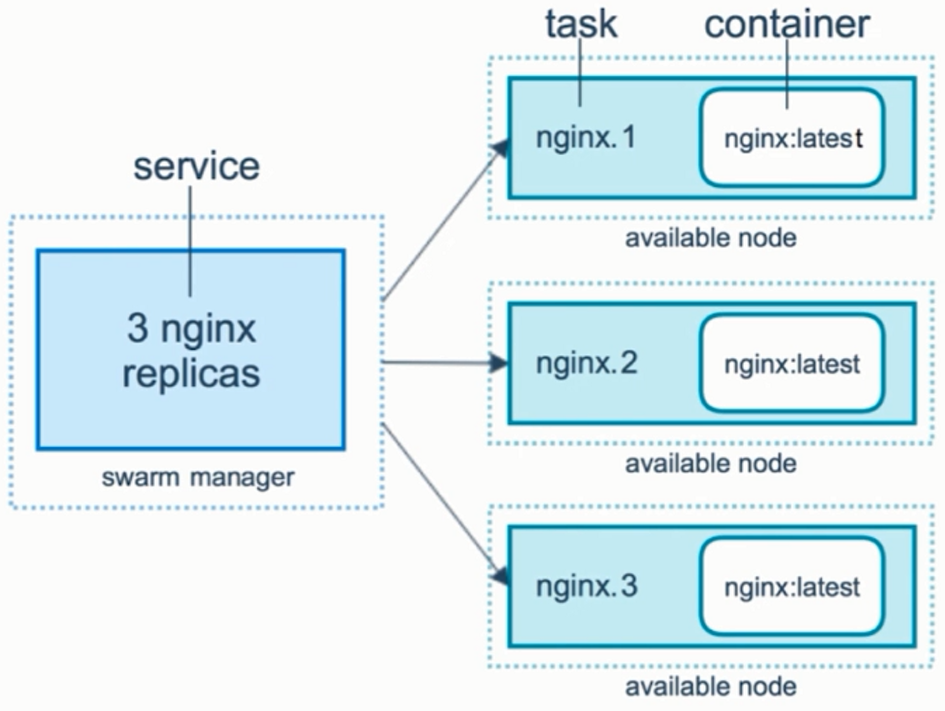
注:此图产生了三个容器,会调度系统调度到不同的节点上去,即该service最终会运行在那些swarm节点上是不知道的
例子:
创建一个三节点的swarm集群:
节点一:
1 | #初始化swarm并创建manager节点,同时指定manager的地址 |
借点二:
1 | #创建worker节点并加入该swarm集群(init后会提供该命令),用于将另一台机器加入称为worker |
节点三:
1 | #创建worker节点并加入该swarm集群(init后会提供该命令),用于将另一台机器加入称为worker |
Service的创建维护和水平扩展
docker service命令类似于docker run,只是不是在本地上运行
1 | #创建一个busybox的service,叫demo |
sudo docker service ls命令显示的REPLICAS栏:- 分母:创建时规定的横向扩展数量(scale)
- 分子:有几个已经ready了
scale命令扩展时,如果有部分节点上的service失效了(退出、shutdown等),系统会在任意节点上再起一个直到达到scale规定的数目
集群服务器通信——RoutingMesh
RoutingMesh的两种体现:
- Internal:Container和Container之间的访问通过overlay网络(通过VIP虚拟IP)
- Ingress:如果服务有绑定接口,则此服务可以通过任意swarm节点的相应接口访问
Internal
docker Compose在单机的情况下,不同的service可以通过对方的名字相互访问(底层通过DNS服务实现)。而在swarm class中,不同的service有可能在不同的节点上,不同的service之间也能通过service name通信,也有DNS服务。
对于Swarm来说,有内置的DNS服务发现的功能,通过service命令创建service时,如果是连接到一个overlay的网络上,会为连接到overlay网络上的所有的service去增加一条DNS的记录,通过该记录就能知道IP地址(并不是实际上该service所在的容器的ip地址,而是虚拟的ip地址,即VIP,一旦service创建好后,VIP就不会改变,但是和具体的ip地址绑定是通过LVS(Linux Virtual Service)实现的),就可以访问其服务
例子:
swarm-manager节点:
1 | #创建overlay网络,命名demo |
进入swarm-worker1节点:
1 | #尚未扩展前: |
- 不管service有几个横向扩展,但是最后的VIP只有一个,而且访问这个VIP时,Swarm会自动做负载均衡,依次轮流访问这几个横向扩展的service
- 上述的负载均衡以及VIP均通过LVS(Linux Virtual Service)实现
Ingress
- 外部访问的负载均衡
- 服务端口被暴露到各个 swarm节点
- 内部通过IPVS进行负载均衡
当我们去任何一台Swarm节点上去访问端口服务的时候,会把该服务通过本地节点的IPVS(IP的virtual service),通过LVS把该服务负载均衡:
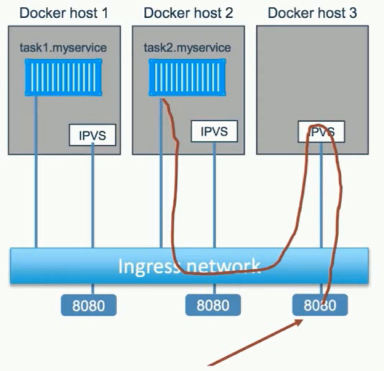
- 当外部访问docker host3的8080端口时(该节点上没有对应service),IPVS会将该请求转发到另外两台具有service的节点上
例子:
swarm-manager节点:
1 | #创建overlay网络,命名demo |
进入swarm-worker1节点:
1 | #获取,发现任可以访问 |
docker stack部署swarm
利用Docker compose file,即yml文件,主要通过deploy命令,官方文档:https://docs.docker.com/compose/compose-file/#deploy
注意:该处的docker compose file中不能利用build命令构建本地image,只能通过远程拉取
以下均为deploy下的子命令:
endpoint_mode:- vip(默认):service之间通过vip互访(底层会通过LVS自动做均衡负载)
- dnsrr:直接使用service的ip地址互访,也会通过dnsrr(DNS round-robin)做均衡负载
labels:帮助信息mode:- global:不能通过scale命令做横向扩展,整个class中只有一个service
- replicated(默认):可以横向扩展
placement:- constraints:
- node.role==manager:一定会部署到manager上
- preferences:
- constraints:
replicas:- 当
mode设置成replicated时,可以在初始化时就指定需要几个service
- 当
resources:资源的限制- cpu:‘0.5’
- memory:20M
restart_policy:重启条件即参数设置- delay:延时
- max_attempts:最大尝试次数
update_config:更新时要遵循的原则- parallelism:并行数(最多能够同时更新几个service)
- delay:延时(每次更新的间隔时间)
例子:
利用yml文件部署wordpress
1 | version: '3' |
进入swarm manager节点:
1 | #语法:sudo docker stack deploy 自定义的名字 --compose-file=xxxx.yml |
密码管理
docker compose file中有些是关于数据库的用户名和密码的,为了安全性考虑需要secret manager
需要加密的部分:
- 用户名密码
- SSH Key
- TLS认证
- 任何不想让别人看到的数据
docker secret management特点:
- 存在 Swarm Manager节点 Raft database里(加密的).
- 多个manager节点通过Raft database确保数据一致
- Secret可以 assign给一个 service,这个 service就能看到这个 secret
- 在 container内部 Secret看起来像文件,但是实际是在内存中
使用例子:
1 | #创建secret |
最典型使用mysql时传入密码的例子:
1 | echo "admin" | sudo docker secret create my-pw - |
docker stack中使用secret
通过secret指定使用哪个secret
例子:
利用yml文件部署wordpress
1 | version: '3' |
service更新
注意:为保证service不会中断,需要保证scale>=2
对正在运行的service进行更新:
1 | #创建overlay网络,命名demo |
七、容器编排Kubernetes
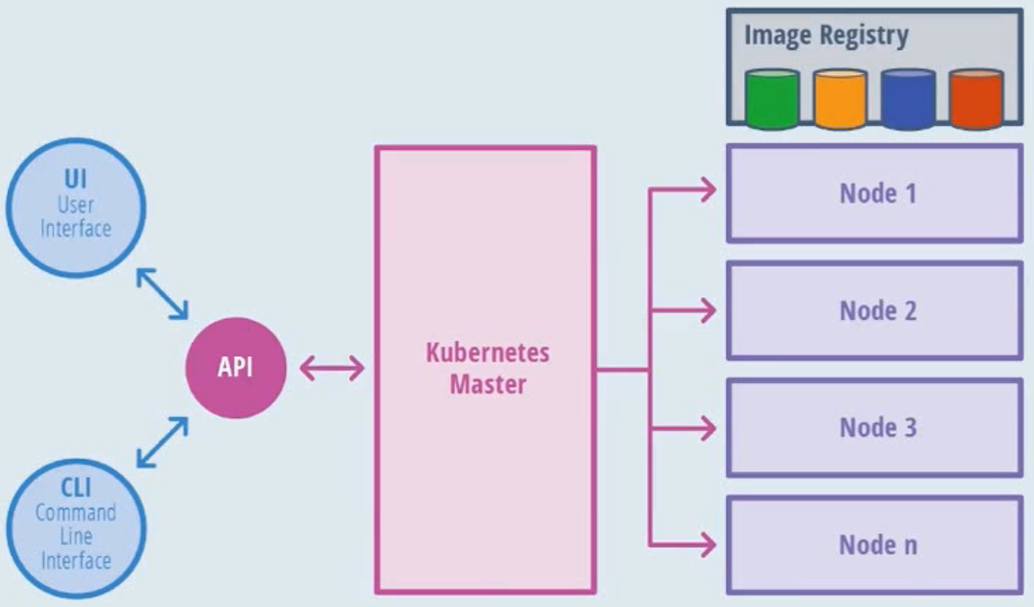
kubernetes架构:
其中Master节点架构:
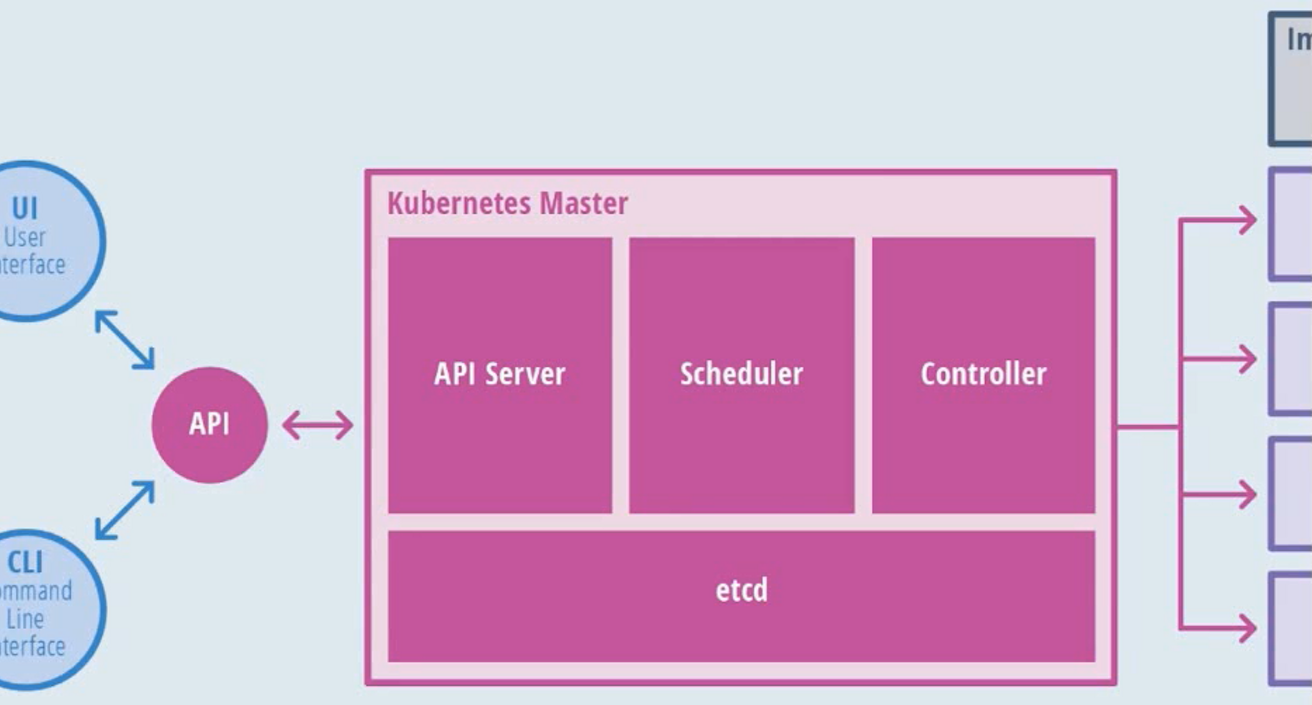
- API Service:暴露给外界访问
- Scheduler:调度模块
- Controller:控制模块,对节点的控制
- etcd:分布式的存储,存储k8s的状态和配置
node节点架构:
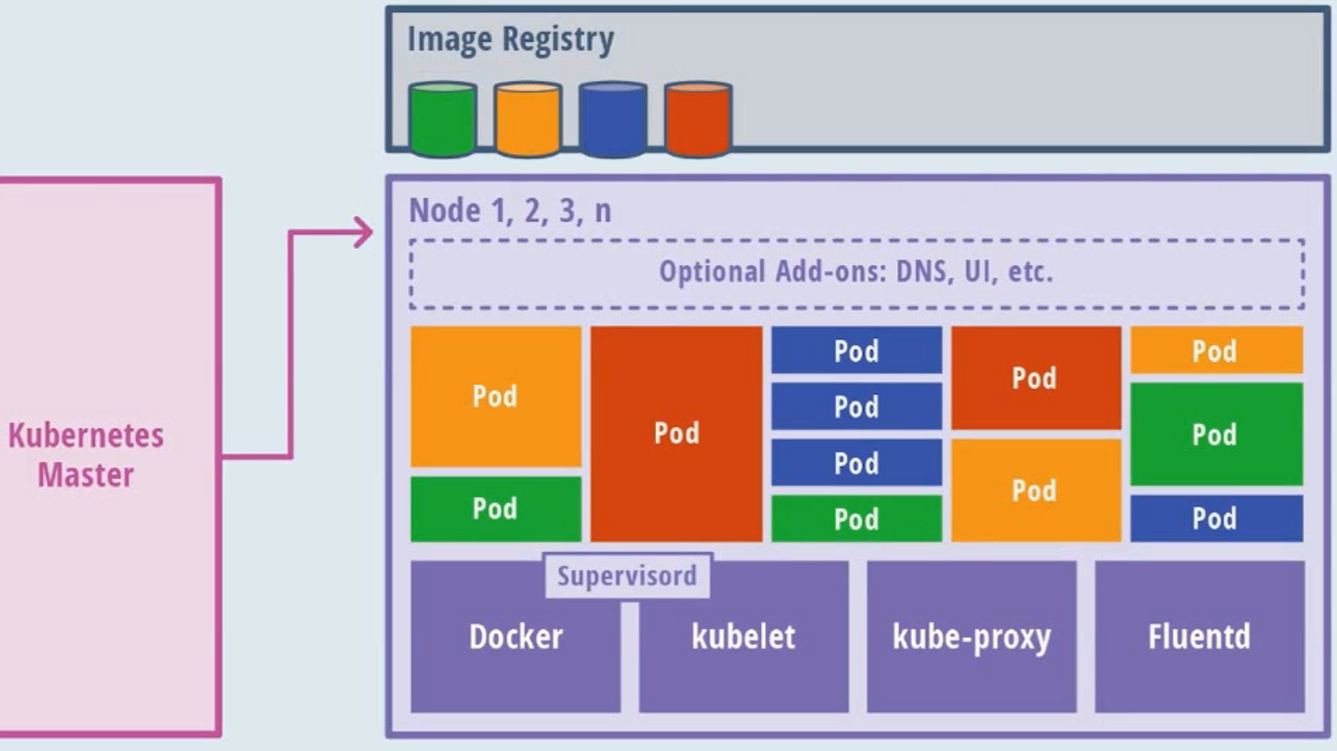
- Pod:在k8s中,是在容器中调度的最小单位,是具有相同的namespace(包含了所有namespace,如user namespace、network namespace)的一些Container组合
- Docker:容器技术之一(k8s中采用docker,还有其他容器技术)
- kubelet:类似于一个代理,受master节点控制,负责在node节点上创建、管理容器、network以及volume
- kube-proxy:端口的代理转发以及service的服务发现和负载均衡
- Flientd:日志的采集、存储、查询
- Optional Add-ons:插件
搭建k8s单节点环境
k8s首席构造师github:https://github.com/kelseyhightower
常用工具介绍:
- kubernetes-the-hard-way:不借助任何脚本,从命令行去操作安装kubernetes
- minikube:本地快速创建一个节点的kubernetes集群
- 通过利用virtualbox创建一台虚拟机,该虚拟机中会安装好kubernetes
- kubeadm:方便的本地搭建多节点的kubernetes集群
- kops:在云上搭建kubernetes集群
- tectonic:少于10个节点免费
- play with kubernetes:网站上搭建,无需任何工作,四个小时保存时间
minikube安装(参考文档):
-
ubuntu上:
1
2
3
4
5
6
7curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube_1.7.2-0_amd64.deb \
&& sudo dpkg -i minikube_1.7.2-0_amd64.deb
#使用以下命令检查下
egrep -q 'vmx|svm' /proc/cpuinfo && echo yes || echo no
#如果输出 no 且如本文一样使用Windows + VirtualBox + minikube,需要通过以下命令创建一个单节点的kubernetes集群(具体命令后文会细说)
sudo minikube start --vm-driver=none#
sudo minikube config set vm-driver none# -
需要安装依赖的
kubectl(客户端的CLI,可看上面的架构图)1
2
3
4
5
6#ubuntu上可以使用该命令安装:
sudo snap install kubectl --classic
#其余Linux发行版可以使用以下命令
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl -
虚拟化工具virtualbox
1
2
3#测试版本号
minikube version
kubectl version
kubectl的上下文:一些配置信息或者认证信息,称之为context,即上下文
kubectl的官方帮助文档
命令:
1 | #创建一个单节点的kubernetes集群(适用于mac或Linux上直接装minikube+virtualbox用户) |
kubectl命令行补全补丁
kubectl自带命令行补全的脚本,通过命令:
1 | #Linux |
进行打补丁补全。其他系统可以参考官方文档最后一节Optional kubectl configurations
最小调度单位pod
Pod是k8s集群中运行部署应用或服务的最小单元,一个Pod由一个或多个容器组成,kubernetes中不对容器进行直接操作。在一个Pod中,容器共享网络和存储,并且在一个Node上运行。
Kubernetes为每个Pod都分配了唯一的IP地址,称之为Pod IP,一个Pod里的多个容器共享Pod IP地址。Kubernetes要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,这通常采用虚拟二层网络技术来实现,例如Flannel、Open vSwitch等。因此,在Kubernetes里,一个Pod里的容器与另外主机上的Pod容器能够直接通信。
pod具有如下的一些特性:
- pod共享一个namespace(包含用户、网络、存储等)
- 如果一个pod中有两个Container,则这两个Container可以直接通过localhost进行通信,如同在本地一个Linux上运行的两个进程
基本操作例子:
pod_nginx.yml文件(根据kubernetes提供的一个API格式定义一个资源,这里是pod):
1 | apiVersion: v1 |
创建及基本管理:
1 | #查看kubernetes集群是否正常 |
横向扩展
ReplicationController种类:
rc_nginx.yml文件:
1 | apiVersion: v1 |
- 通过ReplicationController创建的pod,kubernetes能够自动帮我们维持对应数量的pods
创建:
1 | #根据rc_nginx.yml创建pod |
ReplicaSet种类:
rs_nginx.yml文件:
1 | apiVersion: apps/v1 |
- ReplicaSet是ReplicationController的升级版,ReplicaSet支持new set-based selector
创建:
1 | #根据rs_nginx.yml创建pod |
Deployments
官方文档:https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
Deployments控制器提供了Pod和ReplicaSets的声明性更新。即Deployments会描述一种希望的状态,如有三个扩展(–replicas=3)、pod中的具体的docker image版本以及相关的更新,Deployments controller都会努力使该声明实现(Deployments会通过创建ReplicaSet进而来创建pods)
注意:不能独立对 通过Deployments创建的Pod和ReplicaSets 进行操作(尤其是删除操作)
创建和管理
deployment_nginx.yml文件:
1 | apiVersion: apps/v1 |
创建:
1 | #根据deployment_nginx.yml创建Deployment |
Deployment相关命令:
1 | #查看Deployment |
使用Tectonic搭建本地多节点
Tectonic为CoreOS的产品:收费企业级产品,可免费试用。
搭建本地多节点教程:https://coreos.com/tectonic/docs/latest/tutorials/sandbox/install.html(实测Tectonic下的sandbox已经不能正常获取!!!该实验无法正常进行!!!)
本质是通过vagrant在virtualbox上创建多台虚拟机(CoreOS系统,Container Linux)
修改kubeconfig文件,使kubectl命令同时支持minikube和tectnic(修改kubeconfig文件,添加新的cluster、context、user,具体配置可以参看官方说明),通过以下命令可以进行切换:
1 | #查看目前的上下文变量 |
基础网络Cluster Network
Cluster Network的官方说明
pod_busybox.yml文件:
1 | apiVersion: v1 |
pod_nginx.yml文件:
1 | apiVersion: v1 |
service_nginx.yml文件:
1 | apiVersion: v1 |
w1节点上:
1 | #根据.yml创建pod |
c1节点:
1 | #c1节点ping w1节点上的busybox-pod |
上述网络关系的拓扑图:
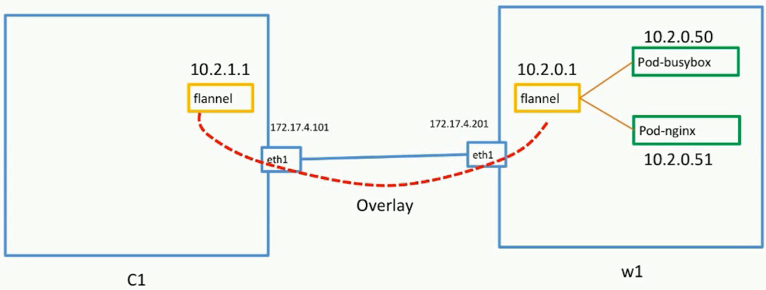
- flannel插件:coreos出品,开源免费,通过该插件实现了两台机器之间的overlay网络
- 诸如flannel插件的其他开源插件还有很多,在本节开头的网址进入后会有其他插件介绍说明以及插件必须遵守的原则
Service
在cluster中,每个pod都有自己独立的ip地址,并且都能够相互ping通,不论pod是否在同一台设备(节点)上(机器本身也能够ping通任意一个pod的ip地址,详见上一节)
注意:不要直接去使用和管理pods:
- 当我们使用 ReplicaSet 或者 ReplicationController 水平扩展 scale 的时候,Pods有可能会被 terminated(终止)
- 当我们使用 Deployment 的时候,我们去更新 Docker Image Version,旧的Pods会被 terminated(终止),然后新的Pods创建
在Kubernetes中,Pod会经历“生老病死”而无法复活,也就是说,分配给Pod的IP会随着Pod的销毁而消失,这就导致一个问题——如果有一组Pod组成一个集群来提供服务,某些Pod提供后端服务API,某些Pod提供前端界面UI,那么该如何保证前端能够稳定地访问这些后端服务呢?这就是Service的由来。
Service在Kubernetes中是一个抽象的概念,它定义了一组逻辑上的Pod和一个访问它们的策略(通常称之为微服务)。这一组Pod能够被Service访问到,通常是通过Label选择器确定的。
创建service:
1、命令行创建
1 | #给pod创建service 供外部访问 |
2、yml文件中通过kind: Service定义,主要有以下三种service
- ClusterIP:ip地址是cluster内部均可以访问的,但是外界缺无法访问(这种内部的ip称为ClusterIP),外界可以通过service的ip访问(一般service的ip不会变动,而pod的ip会变动)
- NodePort:将要访问的port绑定到所有node上,因为node对外可以提供访问(假设node的ip为公网ip),所以该类型的service外界也是可以访问的,但是这种方式暴露的port有范围限制(30000-32767)
- LoadBalancer:一般需要结合云服务使用,由云服务商提供。实际环境中运用较多
- ExternalName:通过DNS的方式。实际环境中运用较多
- Default:即ClusterIP,默认为ClusterIP方式
以上均是通过ip地址访问的,但是其实也是可以通过dns访问,但是需要相关的插件
ClusterIP的相关例子:
例子1:
w1节点上:
1 | #根据上一节.yml创建pod |
c1节点:
1 | curl 10.3.248.3#可以直接通过service访问pod |
例子2:
deployment_python_http.yml文件:
1 | apiVersion: extensions/v1beta1 |
w1节点上:
1 | #docker pull python:2.7 |
c1节点上:
1 | curl 10.2.0.142:8080#可以直接访问pod1 |
w1节点上:
1 | #查看deployment情况 |
c1节点上:
1 | curl 10.3.120.168:8080#可以直接通过service访问pod |
- 访问service ip会自动做一个负载均衡
例子3:
接例子2中的换件,在c1中:
1 | #不停地调用 |
w1节点中:
1 | #直接编辑deployment_python_http.yml 达到应用升级 |
- 修改deployment_python_http.yml文件后,c1中的程序检测到该服务会停止一段时间,但是最后会恢复至正常
- 该更新并不是Rolling Updata,即并不是零宕机更新,有一段时间会存在不能访问服务器
NodePort类型service以及Label简单应用
演示:
service中(c1节点pod_nginx.yml):
创建pod_nginx.yml:
1 | apiVersion: v1 |
- labels:几乎所有的资源都可以设置一个label,由一对key value组成,且可以设置不止一个
1 | #创建pod |
- 直接在浏览器中打开
172.17.4.101:31404或172.17.4.201:31404即可正常访问Nginx
NodePort类型的service会将端口映射到整个Cluster上的每个node的ip地址上,所以可以通过Cluster的任意一个节点的ip地址+端口去访问服务
类似创建pod,该service也可以通过.yml文件(service_nginx.yml)创建:
1 | apiVersion: v1 |
- 注意
selector应该和上文中的pod创建时指名的label一致,指名是该pod
再次创建:
1 | #查看运行中的pod的label是否和yml文件中描述的吻合 |
- 此时,直接在浏览器中打开
172.17.4.101:32333或172.17.4.201:32333即可正常访问Nginx
label例子演示:
由上文中提到的,几乎所有的资源都可以设置一个label,由一对key value组成,且可以设置不止一个,具体使用如下:
pod_busybox.yml文件:
1 | apiVersion: v1 |
创建:
1 | #创建pod |
- pod_busybox状态一直是pending的原因为:整个Cluster中的所有node上的label匹配不到
hardware=good的label,所以该pod一直不能正常部署到node上
1 | #查看所有node上的所有label |