
融合总结
融合总结
在3D对象检测这块有以下几种方法:
- lidar-only:
- 基于投影的
projection-based:FVNet - 基于体素的
voxel-based:VoxelNet-->SECOND-->PointPillars-->fast pointrcnn - 基于点云的
point-based:PointNet-->PointNet++-->PointCNN-->PointRCNN point-voxel:这种是将上述两种进行融合,通过两级神经网络来实现。在第一阶段利用体素对原始点云进行粗略定位与估计边界,第二阶段通过pointnet优化边界3D-SSD:一种新的网络,不需要上述的两阶段融合,直接通过构建一个单阶段的无锚神经网络从候选的三维ROI中回归出物体的三维边界
- 基于投影的
- image-only:
- Pseudo-LiDAR
- Stereo R-CNN
- MULTI-SENSOR FUSION:
MV3D、AVOD:使用现成的2D特征提取器从图像和点云的多维视图(鸟瞰图BEV、正视图等)中获得特征图,再通过求和或串联操作直接融合,然后通过区域建议网络(RPN)用于融合后的特征图得出三维边界,之后通过优化网络确定最终的三维边界Frustum pointnets、Frustum convnet:通过引入三维边界框(3D bounding frustums)来缩小搜索空间。通过三维边界框修剪点云,并将该数据送入pointnets对三位边框进行回归Pointfusion:从现成的2D特征提取器获得的图像的全局特征与从pointnet捕获的点云特征进行融合PointPainting:先将图像分割神经网络的输出与点云密集聚合(densely aggregates)再用lidar-only的3D检测器,以提高3D对象检测任务的性能
PointNet
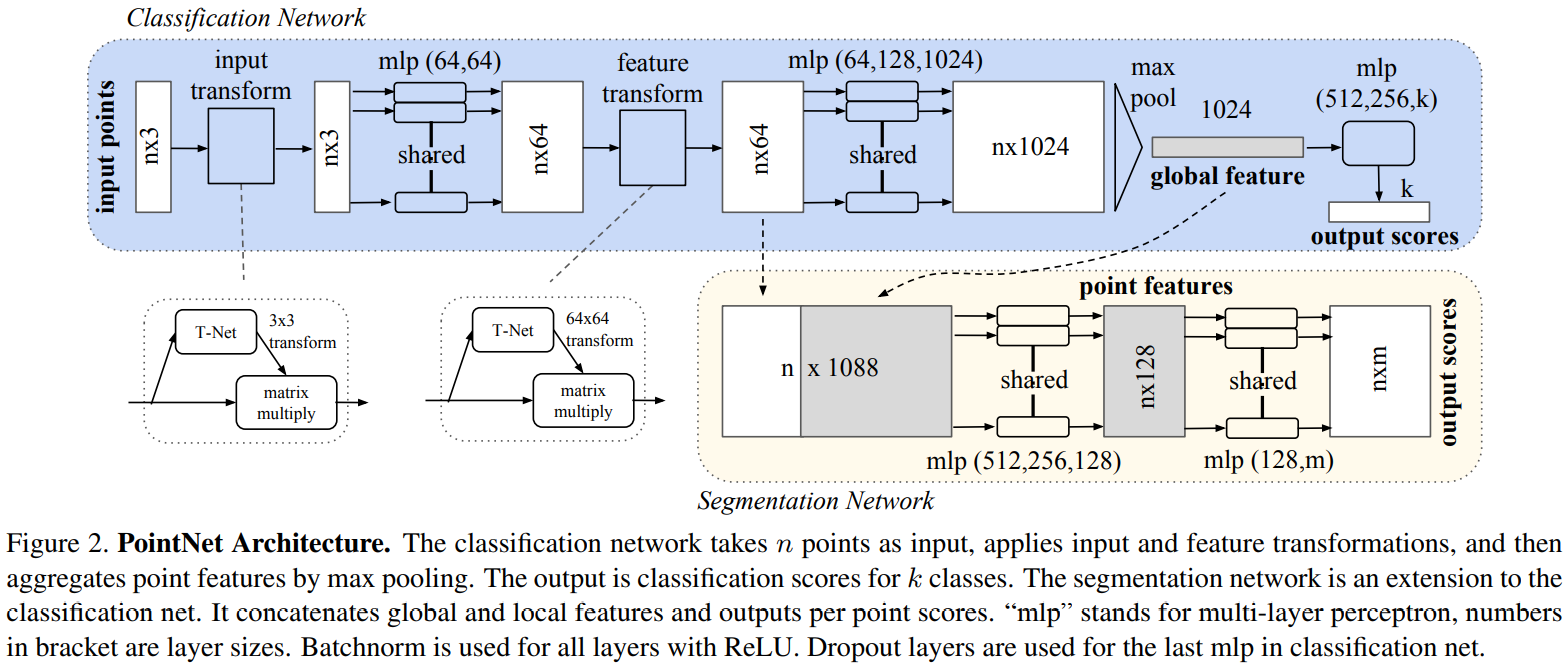
该网络主要解决三个部分:
- 通过一个对称性函数解决输入点云无序问题
- 这个是直接通过mlp(多层状态机)和max pool解决的
- 将局部和全局信息进行融合
- 在分类网络中只需要全局信息即可,但是在分割网络中需要局部和全局信息,所以在分割网络中会将这两部分拿过来作为输入
- 联合调整网络
- 基于点云经过一定的刚性变化后其语义是不变的这个事实,需要对输入进行对齐操作,该部分通过两个T-net解决。
- 第一个T-net解决输入数据的对齐问题。通过T-net预测一个仿射变换矩阵,并直接将该矩阵用于输出数据。该网络是整个分类网络的一个nimi版本,也是通过点特征提取+最大池化层+全连接构成
- 第二个T-net解决特征数据的对齐问题。由于特征空间变换矩阵维度较高(参数较上一个大),需要在softmax层的loss上加上一个正则化项来解决(L2范数)
不足:
- PointNet大部分处理都是针对单个点的,无论提取对么精细的特征,都是针对一个点的,而整合所有采样点特征的部分只有最大池化层,即,网络对于点之间的联系利用不够多,缺少局部信息。因此,网络对于模型局部信息的提取能力远不如CNN。
- 网络对于输入点云的数量是否有要求,即是否需要每个样本的点云数量相同?通过阅读源码,发现Pointnet对原始数据的点云数量没有要求,但是在输入网络训练之前,所有的样本都经过了随机重新采样(中心化以及随机增强),整个过程保证了输入到网络的每个样本的点云的数量都是相同的(可以多不能少),所以严格来讲,网络并不是对样本中点云数量没有要求。
PointNet++
上述Pointnet的最大缺点就是不能有效利用局部信息(局部特征),而且现实中很少有pointnet中那中均匀分布的点云,大多点云的密度都是不一的。为此作者提出以下两种方法:
- 利用空间距离(metric space distances),使用PointNet对点集局部区域进行特征迭代提取,使其能够学到局部尺度越来越大的特征。
- 由于点集分布很多时候是不均匀的,如果默认是均匀的,会使得网络性能变差,所以作者提出了一种自适应密度的特征提取方法
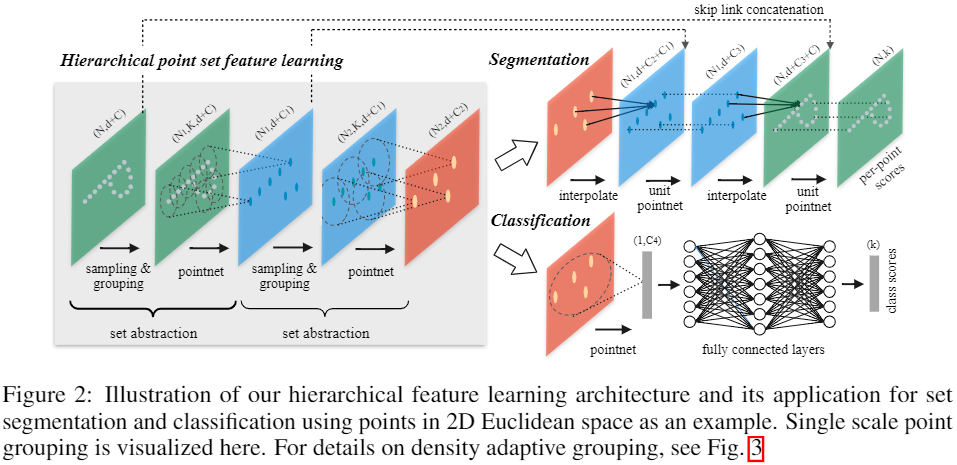
该网络是在PointNet的基础上加入了多层次结构(hierarchical structure)来实现的,其中重要的是SA层(set abstraction layers),主要由三部分组成:
Sample layer:对输入点进行采样,在这些点中选出若干个中心点- 使用farthest point sampling选择N’个点(能更好的的覆盖整个点集)。至于点的数量是手动定的
Grouping layer:利用上一步得到的中心点将点集划分成若干个区域- 使用Ball query方法生成N’个局部区域(这里有两个变量 ,一个是每个区域中点的数量K,另一个是球的半径,且均由手动指定)
ointNet layer:对上述得到的每个区域进行编码,得到特征向量- 输入:
N'×K×(d+C)。输出:N'×(d+C)
- 输入:
SA层的输入为N*(d + C),输出是N'*(d + C'),其中:
N:输入点的数量N':输出点的数量d:坐标维度C:特征维度C':新的特征维度
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 spaceman!

