
Xtensa基础
WARNING
Xtensa 的指令集架构类似于 RISC,并对嵌入式应用场合做了多种优化。在移植操作系统时要留意以下几方面:
- 变长指令
- 窗口(window)寄存器
- 处理器的可配置性
- 处理器的可扩展性(可通过 TIE 描述语言为 Xtensa 添加新的指令)
Xtensa 处理器的硬件抽象层 HAL
TIP
HAL 向上提了供统一的接口,向下屏蔽了 Xtensa 处理器的不同配置。
编译时 HAL(CHAL)
包括 C 预处理器与汇编宏定义(用来表征 Xtensa 处理器的具体配置),确保源码级别的兼容性。
链接时 HAL(LHAL)
对于 Xtensa 处理器的不同配置均适用,底层软件(如操作系统移植层)可以通过调用该层接口来处理 ISA 相关的操作(如保存现场 window frame )。
编写汇编代码
示例 C 程序:计算斐波那契数列
1 | unsigned int fib(unsigned int val) |
将该代码汇编后得到如下汇编程序:
1 | .text # 将以下代码编译进 .text 段 |
TIP
Xtensa 中的某些指令可以通过加后缀 .n 可以让编译器尽量使用 16 比特的指令,以冀获取更高的代码密度
窗寄存器函数调用规范 (Windowed Calling Convention)
现代处理器为了更好的支持高级编程语言的高效编译,通常处理器所拥有的通用寄存器的数目有16个甚至32个之多,如此多的寄存器在比较复杂的应用程序上实现深度嵌套调用的时候,为了保证程序的正确执行,寄存器要频繁地进行入栈和出栈的操作,这样频繁的堆栈memory的访问将明显恶化应用程序的性能。为了有效解决这一问题,Xtensa架构设计了一种Windows旋转方式的寄存器管理机制,将逻辑寄存器和物理寄存器分开,在函数调用的时候通过windows滑动切换逻辑寄存器,从而避免寄存器覆盖,减少压栈和出栈的操作。
AR物理寄存器环形Buffer
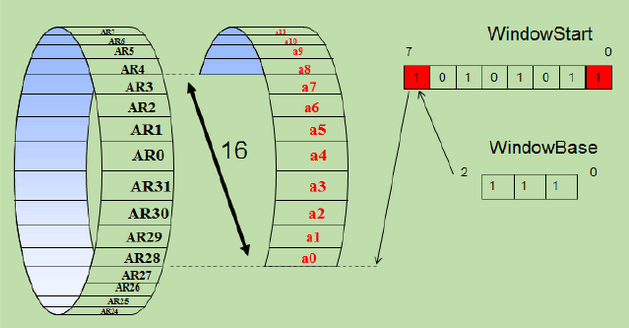
基本实现原理:使用更多的物理AR寄存器组成一个环形的buffer。这些寄存器每4个为一组(pane),WindowStart中的每个比特依次表示该组是否作为逻辑寄存器窗口的起始位置或者被占用。当前的逻辑寄存器的起始位置则用WindowBase状态寄存器来表示。在发生函数调用的时候是通过修改WindowBase寄存器,滑动逻辑寄存器窗口,从而父子函数看到的是不同的物理寄存器,避免了寄存器的压栈和出栈。
以每4个寄存器(pane)为单位,函数调用的时候窗口可以滑动4个,8个或者12个物理寄存器,分别可以用call4,call8,call12指令来实现,而最典型的应用则为call8。
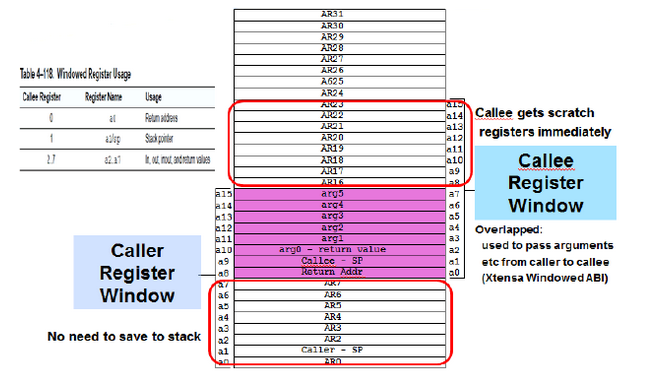
- a0用来保存函数返回地址
- a1保存sp堆栈指针
- a2~a7用来传递函数入参,参数超过6个的时候则需要使用堆栈
- 对调用者函数和被调用函数来说,a0~a7是独立的寄存器,可以自由使用,而a8~a15则为scratch寄存器,随时会被子函数使用,调用者函数如果要使用,则在调用子函数前进行压栈保存
为了方便寄存器正常的保存与恢复,还要调用栈的高效回溯,还有必要对函数的Frame栈空间做统一的安排。
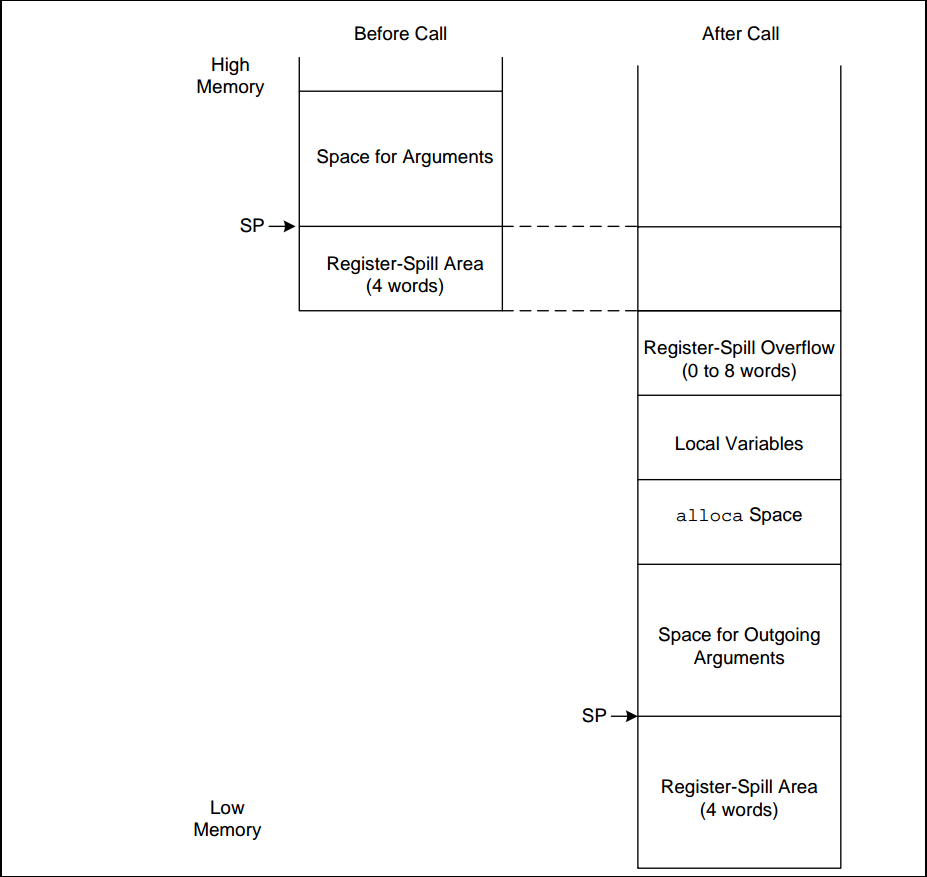
- Base Area用于存储其父函数的基本寄存器
a0~a3
Windows寄存器覆盖问题
在发生函数调用,执行call指令的时候,窗递增值(call4,call8,call12分别对应1,2,3)存入PS处理器状态寄存器的CALLINC域,在进入函数的入口处用entry指令进行Window重叠检测,条件满足的时候将触发相应的windows overflow异常,引导程序进行覆盖寄存器的入栈保护。
Windows寄存器underflow问题
当子函数返回时,RETW或者RETW.N指令执行,此时也仅此时处理器将进行上溢检查。如果当Windowbase所在的位置的前3个windows pane的WindowStart比特都为0,则意味着它返回后的父函数发生过WindowOverflow,父函数的窗口寄存器曾经被压入stack。如果不是全为0,则应该不为零0的点和正常window返回的点对应,就返回,如果不同,则说明发生了不正常的调用,a0被破坏掉了,要产生非法指令错误。
参数传递
前6个参数会传递给 AR 寄存器,剩余的参数会被保存在stack中。
对于callN指令(N取值4,8或者12)来说,函数调用者会将参数保存到寄存器AR[N+2]到AR[N+7]中(特别注意,call12指令是能用于调用只有两个或者更少参数的函数,只能使用AR[N+2]和AR[N+3]寄存器),函数被调用者会从寄存器AR[2]到AR[7]中接收这些参数。
如果参数的数量多于6个,剩下的参数就会被保存在函数调用者的堆栈,即第七个参数保存在[sp+0]处,第八个参数保存在[sp+4]处,依此类推。函数被调用者需要从内存的[sp+FRAMESIZE]处获取这些额外的参数,其中FRAMESIZE是被调用者的stack frame大小,通常会用entry指令指定。
以下C程序代码
1 | int func( int a, int b, int c, int d, int e, int f, |
对应的汇编程序代码为
1 | .align 4 |
函数调用与返回
每个C语言函数的调用都会通过以下的指令来实现:call4,call8,call12,callx4,callx8,callx12。为了给函数传递控制信息,这些指令会在PS.CALLINC中设置Window Increment(即逻辑窗旋转的量),同时也会将被调用者的a0寄存器(可能是调用者的a4,a8或者a12寄存器)设置返回地址(该寄存器的高两位会用来保存逻辑窗增量)。return指令会将逻辑窗重新旋转回原来的位置(通过读取返回地址的高两位来确定旋转量)。相反地,entry指令只能通过PS.CALLINC的值来旋转逻辑窗(因为它不知道究竟是哪一个寄存器会用来保存返回地址)。
每个函数都要分配一个堆栈帧(stack frame),其大小由两方面决定:
- 该函数用到的本地变量(如果有用到,就需要计算进去)
- 窗口保存区(window save area)
每个函数必须要分配16字节给基本保存区(base save area),如果一个函数还使用了call8或者call12指令,那就需要在堆栈帧中给附加保存区(extra save area)分配空间。如果是call8指令,需要额外分配16字节(总共32字节);如果是call12指令,需要额外分配32字节(总共48字节)。如下表所示
| 函数中执行的操作 | 额外需要的堆栈帧空间(单位:字节) |
|---|---|
| No Calls | 16 |
| call4 | 16 |
| call8,call4 | 32 |
| call12,call8,call4 | 48 |
entry指令
主要做两件事情:
- 它根据调用者的堆栈指针计算被调用者的堆栈指针,并使用该命令后跟的立即数作为堆栈帧的大小。
- 根据
PS.CALLINC的值旋转逻辑窗
Xtensa汇编代码简单示例
部分底层驱动只能使用汇编语言编写,比如:
- 用户异常处理
- 内核异常处理
- window处理
- 复位处理
使用汇编实现16比特点积运算
1 | #include "dsls_dotprod_16s_m_ae32.S" |
- 有些指令会以
.n作为后缀,Xtensa处理器为了进一步提高代码密度,提供了一些常用指令的16比特版本,这里的n代表narrow
指定段名
1 | /* |
.section指令后需要跟上段名和附加信息(用于描述该段的属性),x表示可执行,a表示可分配- 在
.begin literal_prefix和.end literal_prefix之间的所有字面量会被放在特殊的段中(不是默认的.literal),这个段的前缀名由用户指定
编写高效的汇编代码
分支预测
经验法则:进入分支比不进入分支的开销更大
手动调度指令
经验法则:预测流水线气泡,将其替换成有用的工作
防止逻辑窗口溢出
经验法则:优先使用最低编号的寄存器
当逻辑窗口在物理寄存器文件中旋转时,有可能会发生窗口溢出,此时需要对其余函数的上下文进行保存,会带来额外的开销。所以如果函数仅仅使用两个寄存器,那就选择a2和a3,使用a4~a15中的任何一个都可能会造成窗口溢出。如果函数需要使用3个寄存器,选择a2,a3外加a4-a7中的任何一个,这四个寄存器是在同一片寄存器玻璃(window pane)上,所以他们触发窗口溢出的概率是一样的。
获取程序计数器(PC)
Xtensa架构没有提供读取PC值的指令,推荐使用如下代码来读取PC值:
1 | movi a2, 1f |
尽量使用coreasm.h中的宏定义来屏蔽不同处理器的差异
常用的功能有:
- 查找寄存器中被设置的最高或者最低的有效位
- 循环构造器
- 有条件地读取和设置中断级别
- 窗口溢出功能
Xtensa的异常架构
程序状态(PS)寄存器

本文转载自suda-morris个人博客

