
Kubernetes
组件说明
kubernetes前身Borg系统架构:
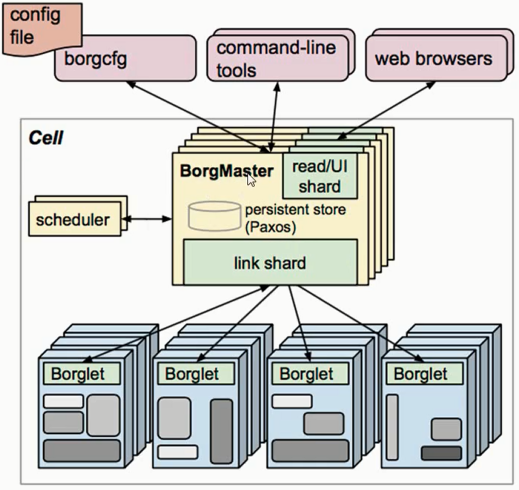
- BorgMaster:主要负责请求的分发,整个集群的大脑
- 多个,避免单节点故障,一般高可用集群的最好保持3个以上,一般为奇数,即3,5,7,9等
- link shared:分发
- Borglet:真正执行的节点
- scheduler:调度器,会将数据写入Paxos(数据库)
- borgcfg、command-line tools、web browsers:通过 一些配置文件、命令行、浏览器 对这个集群进行调度管理
kubernetes架构:
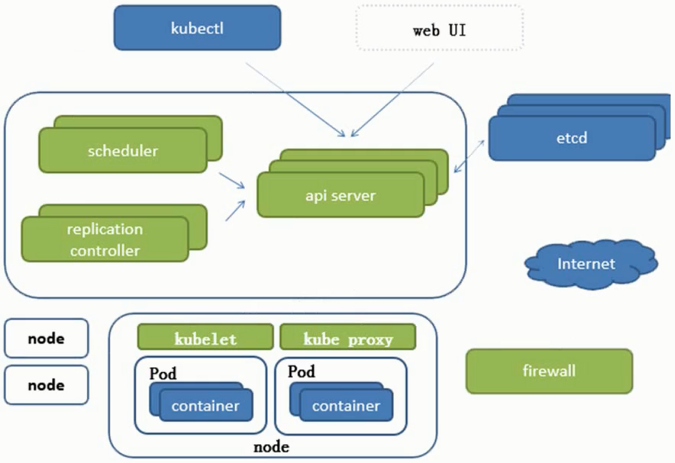
- kubectl、web UI:命令行管理工具、网页
- etcd:GO语言的开源项目,键值对数据库,起持久化作用,储存k8s集群中的所有重要信息
- etcd的官方将它定位成一个可信赖的分布式键值存储服务,它能够为整个分布式集群存储些关键数据,协助分布式集群的正常运转,有以下两个版本:
- v2:会将所有数据写入内存中
- v3:会引入本地化 卷的持久化操作,关机后数据不会丢失(k8s 1.11之前没有该版本)
- Master(上边大框):领导者
- scheduler:调度器,调度任务至不同的node中,会将任务交给api server
- api server:负责将请求写入etcd,一切服务、访问的入口
- replication controller:重置器,维护副本数目或者期望值
- node(下面小框):执行者
- kubelet:根CRI(C:container容器 R:Runtime运行环境 I:interface接口 ,即docker在这里的表现形式)有关。kubelet会跟docker进行交互,操作docker创建对应的容器,维持pod生命周期
- kube_proxy:实现pod与pod之间的访问,包括负载均衡。默认操作防火墙(firewall)实现pod的映射。新版本中支持IPVS。
- docker或其他虚拟化引擎
ETCD内部架构图:
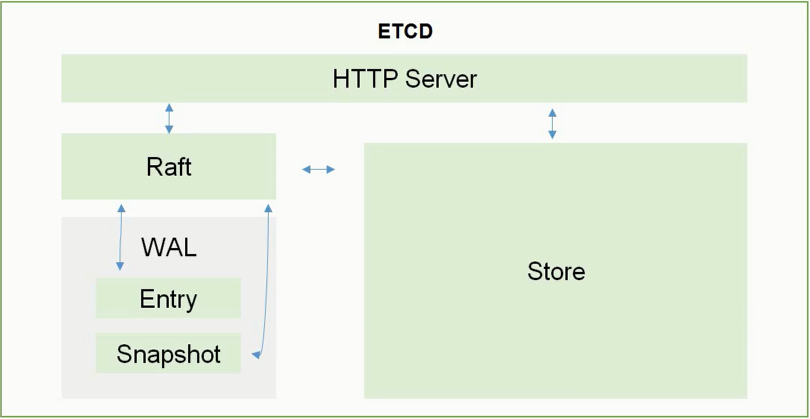
- Raft:所有读写信息都在这里
- WAL:预写日志
- Entry:日志完整备份
- Snapshot:日志临时备份
- Store:Raft会将数据以及日志写入磁盘中进行持久化设置
相关插件:
- COREDNS:可以为集群中的SVC创建一个域名IP的对应关系解析
- DASHBOARD:给K8s集群提供一个B/S结构访问体系
- INGRESS CONTROLLER:官方只能实现四层代理, INGRESS可以实现七层代理
- FEDERATION:提供一个可以跨集群中心多K8S统一管理功能
- PROMETHEUS:提供K8s集群的监控能力
- ELK:提供K8s集群日志統一分析接入平台
基础概念
Pod概念
只要pod运行,pod中的pause容器就一定会被启动,且该pod中的其他容器会共用pause容器中的网络栈和存储资源
- 共用网络栈:其他容器中没有独立的ip地址,有的只有pause容器中的或该pod的地址,即其他容器均可通过localhost访问对方,同时也表示同一个pod中容器之间的端口不能冲突(一样)
- 共用存储资源:同一个pod中既共享网络又共享储存
分类:
- 自主式Pod:不是控制器管理的pod,一旦死亡就结束
- 控制器管理的Pod
pod控制器类型:
- RC(ReplicationController) & RS(ReplicaSet) & Deployment:
- ReplicationController用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收。在新版本的 Kubernetes中建议使用 ReplicaSet来取代 ReplicationController
- ReplicaSet跟 Replication Controller没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector
- 虽然 ReplicaSet可以独立使用,但一般还是建议使用 Deployment来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如 ReplicaSet不支持rolling-update但Deployment支持,Deployment是通过创建ReplicaSet来创建新的容器进而达到滚动更新的目的,且更新或者回滚时之前创建的ReplicaSet会被停用(而非删除))
- HPA(HorizontalPodAutoScale):
- Horizontal Pod Autoscaling仅适用于 Deployment和 ReplicaSet(HPA是基于RS定义的),在v1版本中仅支持根据Pod的CPU利用率扩所容,在 v1 alpha版本中,支持根据内存和用户自定义的 metric扩缩容,即能够实现水平自动扩容
- StatefullSet
- StatefullSet是为了解决有状态服务(无状态服务:没有状态需要实时保留,或拿出来一段时间后放回去仍能够正常工作。反之为有状态服务)的问题(对应 Deployments和 ReplicaSets是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即Pod死亡后重新调,还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其 PodName和 HostName不变,基于 Headless Service
(即没有 Cluster IP的 Service)来实现 - 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是 Running和 Ready状态),基于 init containers来实现
- 有序收缩,有序删除(即从N-1到0)
- StatefullSet是为了解决有状态服务(无状态服务:没有状态需要实时保留,或拿出来一段时间后放回去仍能够正常工作。反之为有状态服务)的问题(对应 Deployments和 ReplicaSets是为无状态服务而设计),其应用场景包括:
- DaemonSet
- DaemonSet确保全部(或者一些(通过在Node上打污点(不被调度的Node),将不会在打污点的Node上运行该Pod副本))Node上运行一个Pod的副本。当有Node加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,这些Pod也会被回收。删除 DaemonSet将会删除它创建的所有Pod。DaemonSet的一些典型用法:
- 运行集群存储 daemon,例如在每个Node上运行 glusterd、ceph
- 在每个Nde上运行日志收集 daemon,例如 fluent、 logstash
- 在每个Node上运行监控 daemon,例如 Prometheus Node Exporter
- DaemonSet确保全部(或者一些(通过在Node上打污点(不被调度的Node),将不会在打污点的Node上运行该Pod副本))Node上运行一个Pod的副本。当有Node加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,这些Pod也会被回收。删除 DaemonSet将会删除它创建的所有Pod。DaemonSet的一些典型用法:
- Job、Cronjob
- Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
- Cron Job管理基于时间的Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
服务发现:
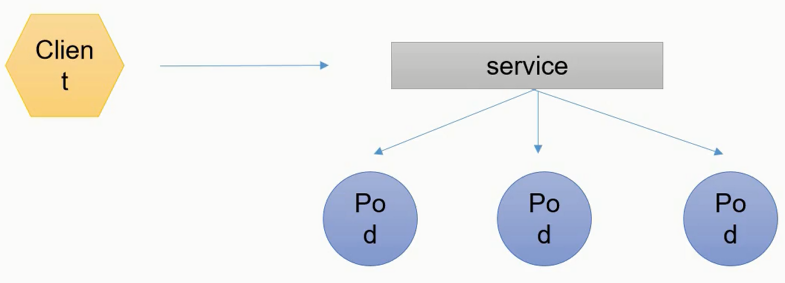
- 客户端想访问一组pod,这组pod会被service通过label选择到,同时service会有自己的ip+端口。所以客户端能够通过service的ip+端口访问从而间接访问service对应的pod,且该处有一个RR(轮询,负载均衡)算法存在
- 一组pod:这些pod均具有相关性,即同一个RS、RC控制器创建或者是拥有同一组标签(本质是通过标签label)
网络通讯方式
Kubernetes的网络模型假定了所有Pod都在一个可以直接连通的扁平(所有的pod均可以通过对方的ip"直接到达"(底层有相关的转化机制,详见后文Flannel))的网络空间中,这在GCE( Google Compute Engine)里面是现成的网络模型,Kubernetes假定这个网络已经存在。而在私有云里搭建 Kubernetes集群,就不能假定这个网络已经存在了。我们需要自己实现这个网络假设,将不同节点上的 Docker容器之间的互相访问先打通,然后运行 Kubernetes
三种方式:
- 同一个Pod内的多个容器之间:lo(localhost,由pause容器的网络栈构成)
- 根本原因:同一个Pod共享同一个网络命名空间,共享同一个 Linux协议栈
- 各Pod之间的通讯:Overlay Network(全覆盖网络)
- Pod1与Pod2不在同一台主机,Pod的地址是与 docker0在同一个网段的,但 docker0网段与宿主机网卡是两个完全不同的IP网段,并且不同Node之间的通信只能通过宿主机的物理网卡进行.将Pod的IP和所在Node的IP关联起来,通过这个关联让Pod可以互相访问(Flannel插件的原理,详解下文)
- Pod1与Pod2在同一台机器,由 Docker0网桥直接转发请求至Pod2,不需要经过 Flannel
- Pod与 Service之间的通讯:各节点的 Iptables规则(最新版本中利用LVS机制)
- Pod到外网:Pod向外网发送请求,查找路由表,转发数据包到宿主机的网卡,宿主网卡完成路由选择后, iptables执行 Masquerade转换,把源IP更改为宿主网卡的IP,然后向外网服务器发送请求
- 外网访问Pod:借助Service的Nodeport方式进行映射
Flannel是CoreOS团队针对 Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的 Docker容器都具有全集群唯一的虚拟IP地址。而且它还能在这些IP地址之间建立一个覆盖网络(Overla Network),通过这个覆盖网络,将数据包原封不动地传递到目标容器内
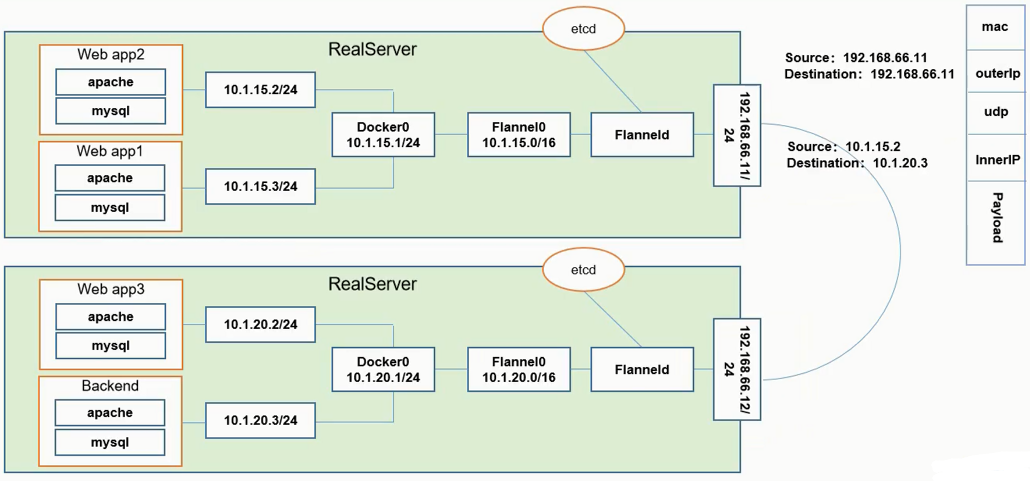
- 所有流量访问Backend的pod上,经过自己的网关处理后将相关请求分配至对应的Web appx服务上。这里的Backend与Web appx的相互之间的访问需要跨主机或者在同主机内部通信
- 服务器service上一般会安装一个守护进程Flanneld,该进程会监听一个端口,该端口是用于后期转发接收数据包的服务端口,同时会开启网桥Flannel0
- 网桥Flannel0会收集Docker0转发出来的数据包
- Docker0会分配自己的ip到对应的pod上
- 同一台主机的不同pod访问:
- 由于均处在同一网桥下,所以数据包都从Docker0的网桥走(在主机内部已经完成了数据包的转换)
- 跨主机不同pod访问(Web app2 --> Backend):
- 设置源、目标地址:10.1.15.2/24–>10.1.20.3/24
- 由于不是同一个网段,所以会发往网关Docker0,Docker0会将数据包传给Flannel0中,Flannel0同样会将数据包传给Flanneld
- Flanneld会从etcd中获取一堆路由表记录,并根据该表判断路由到那一台机器。然后会根据数据报文按照右侧图例进行封装(图中mac层后outerIp中目标地址为192.168.66.12,这里图中错了,注意)
- 数据包会被下面一台service中的Flanneld截获,并拆封该数据包,同时将数据包往Flannel0中发送,Flannel0又会转发给Docker0
- Docker0会再次解封数据包,并将真正的数据发送给Backend
ETCD和Flannel之间的关联:
- 存储管理 Flannel可分配的IP地址段资源
- 监控ETCD中每个Pod的实际地址,并在内存中建立维护Pod节点路由表
K8s中的三层网络关系:
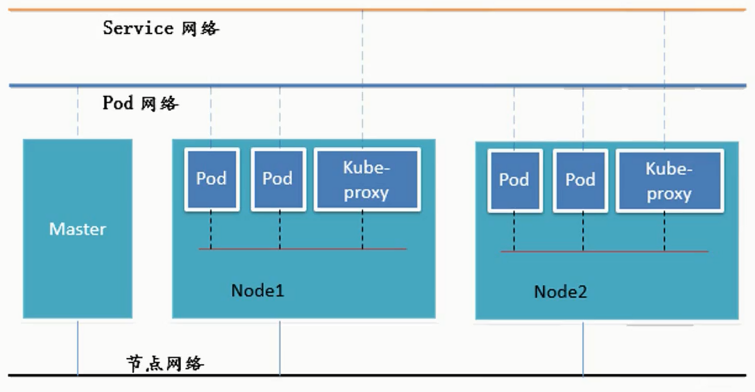
- 真实的物理网络只有:节点网络,其余网络均为虚拟化网络
- 所有Pod均在扁平化网络Pod网络中通信
- 访问Service需要在Service网络中访问,service会通过 LVS/iptables 在后台访问其他pod
Kubernetes集群安装
前期准备
基本情况:私有镜像Harbor(192.168.66.100)、主节点k8s-master01(192.168.66.10)、从节点k8s-node01(192.168.66.20)、k8s-node02(192.168.66.21)以及软路由Router(192.168.66.1)
- 采用k8s官方提供的安装工具kubeadm构建
- Router采用koolshare构建
- 节点及私有镜像均采用CentOS7
集群安装
软路由koolshare搭建
VMware创建软路由koolshare:Windows10 x64(在PE中进行软路由的写入),固件类型为BIOS,2核心,暂时4G RAM后期再修改,网络类型为仅主机模式,磁盘类型为IDE,20G单个文件
步骤:
- 将CD/DVD选项填入老毛桃的image(iso文件)位置,再开启虚拟机,选择进入Windows10 64位PE
- 进入虚拟机后,换掉光盘,换成koolshare的iso镜像文件
- 进入PE中我的电脑,打开DVD驱动器,看到
IMG写盘工具.exe,右键,管理员方式运行,确定后选择对应的20G的物理硬盘,并将映像档设为DVD驱动器中的openwrt-koolshare镜像文件 - 点击开始,写入软路由koolshare
- 写入完毕后,将VMware中的CD/DVD中的设备状态栏中
启用时连接选项关闭 - 关闭Windows10 PE
- 再次调整虚拟机资源:1G RAM,1核心,添加网卡并设为NAT模式
- 之前的网卡为仅主机网络,用于和其他的k8s节点连接
- 添加的NAT网卡用于连接物理机,用于上网
- 在koolshare上安装ssr插件,进行科学上网
- 再次开启虚拟机,会进入koolshare的系统
- 假设安装节点网络为192.168.66.0/24网段,其中master端口为192.168.66.10/24,node1为192.168.66.20/24,node2为192.168.66.21/24
- 修改网络并安装ssr插件:
- Windows控制面板中找到
网络连接,选中仅主机网络对应的网卡(可以通过VMware中的虚拟网络编辑器查看),将对应网卡中IPv4协议中的自动获得IP地址改为使用下面的IP地址,并设置为192.168.1.240,子网掩码:255.255.255.0。点击高级,在IP地址栏中添加一个地址:192.168.66.240,子网掩码:255.255.255.0(一张网卡,两个地址,为了之后koolshare更改ip准备) - Windows物理机中可以打开网页:192.168.1.1的koolshare后台,密码为koolshare
- 找到网络->接口,删除DHCPv6的WAN6
- 编辑内网网卡 LAN:点击
物理设置,关闭桥接 - 编辑外网网卡 WAN:点击
物理设置,没有桥接,正常,无需操作 - 编辑
IPv4地址为:192.168.66.1(此后koolshare后台地址变为了该地址)
- 编辑内网网卡 LAN:点击
- 重进后台,找到网络->诊断,尝试ping百度,测试网络
- 点击
酷软,安装离线插件koolss_2.2.2.tar.gz(安装ssr插件) - 配置上述插件的SS/SSR节点信息并保存
- Windows控制面板中找到
节点及k8s搭建
VMware创建3台centos7机器,分配100G磁盘并存储为单个文件(提高读写IO),4核心,并分别命令为主节点k8s-master01、从节点k8s-node01(4G RAM)、k8s-node02(4G RAM)
网络配置:
1 | vi /etc/sysconfig/network-scripts/ifcfg-ens33 |
环境配置步骤:
1 | #设置系统主机名以及Host文件的相互解析 |
部署安装k8s:
1 | #kube-proxy开启ipvs的前置条件 |
上述过程后,所有节点的基本环境差不多搭建完成,还需要最后做一点工作:
首先初始化master节点:
1 | #安装 Kubeadm (主从配置) |
-
初始化主节点中,若使用现有的镜像文件:
1
2#解压压缩文件
tar -zxvf kubeadm-basic.images.tar.gz -
编写shell脚本load-image.sh一起倒入全部镜像:
1
2
3
4
5
6
7
8
9
10
ls /root/kubeadm-basic.images > /tmp/image-list.txt
cd /root/kubeadm-basic.images
for i in $( cat /tmp/image-list.txt )
do
docker load -i $i
done
rm -rf /tmp/image-list.txt -
执行脚本
1
2chmod a+x load-image.sh
./load-image.sh -
传给另外两台节点
1
2
3
4
5
6
7#传给node01的家目录下
scp -r kubeadm-basic.images load-image.sh root@k8s-node01:/root/
#传给node02的家目录下
scp -r kubeadm-basic.images load-image.sh root@k8s-node02:/root/
#另外两台子节点分别执行脚本,导入image
./load-image.sh
然后需要给master节点中的k8s网络装上Flannel网络插件,实现网络扁平化:
1 | kubectl get node # 查看节点信息 可以发现目前节点还是NotReady状态(还没有Flannel插件构建网络) |
其他节点的加入:
1 | #kubeadm-init.log文件中的最后几行会保存其他节点加入该网络的信息 |
-
注意:默认
kubeadm join命令默认的令牌token有效期为24小时,master节点可以通过如下命令对令牌进行操作(参考链接):1
2
3
4
5
6
7
8
9#创建一个引导令牌
kubeadm token create [token]
#参数:--ttl duration 默认值:24h0m0s 令牌有效时间,超过该时间令牌被自动删除。(例如: 1s, 2m, 3h)。如果设置为 '0',令牌将永远不过期。
#删除指定的引导令牌
kubeadm token delete [token-value] ...
#列出所有的引导令牌
kubeadm token list -
node节点加入格式(参考链接):
1
kubeadm join 192.168.199.10:6443 --token 令牌 --discovery-token-ca-cert-hash sha256:46156bf0422bbca50c2588200c87c9d8d609b9eb5ac5d91c66a129703a0503f6(该值在master初始化时确定)
安装过程中遇到的坑:node节点安装好后一直加入不了master节点中的网络,只输出以下信息:
通过如下方法查询可能出现的问题:
2
kubectl get pod -n kube-system发现两个coredns pod均不是Running状态,均为CrashLoopBackOff,大致找到问题所在,通过日志查看详细情况:
2
3
4
5
#输出如下
E0318 09:27:20.034010 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:322: Failed to list *v1.Namespace: Get https://10.96.0.1:443/api/v1/namespaces?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host
E0318 09:27:20.034010 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:322: Failed to list *v1.Namespace: Get https://10.96.0.1:443/api/v1/namespaces?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host
log: exiting because of error: log: cannot create log: open /tmp/coredns.coredns-5c98db65d4-ksqvt.unknownuser.log.ERROR.20200318-092720.1: no such file or directory发现是
k8s coredns connect: no route to host问题,在github上查到相关链接发现是iptables没有刷新的问题,遂在该问题下找打了答案:
2
3
4
iptables --flush
iptables -tnat --flush
systemctl start kubelet && systemctl start docker之后coredns pod一切正常node节点能够链接到master节点上。
私有仓库Harbor搭建
VMware创建私有镜像Harbor:2核心,2G RAM,100G单个文件。安装CentOS7,基本安装和上文中的节点类似这里不再叙述,值得一提的是该系统中Docker需要安装完毕IP配置为192.168.66.100且内核需要升级到4.4。
修改所有节点及私有仓库Harbor的docker配置文件:
1 | vim /etc/docker/daemon.json |
insecure-registries:默认docker仓库是一个https的访问,需要一个https的证书,这里会在局域网内部制作一个假的证书,该证书对整个k8s集群来说会认为是一个危险的证书,需要通过该参数来将该域名对应的证书加到白名单中
安装Harbor:
从Harbor的官方地址下载压缩包,这里采用harbor-offline-installer-v1.2.0.tgz
1 | #下载docker-compose |
harbor.cfg中的相关参数:- hostname: 目标的主机名或者完全限定域名
- ui_url_protocol: http或https。 默认为http
- db_password: 用于db_auth的MySQL数据库的根密码。 更改此密码进行任何生产用途
- max_job_workers: (默认值为3) 作业服务中的复制工作人员的最大数量。 对于每个映像复制作业,
工作人员将存储库的所有标签同步到远程目标。 增加此数字允许系统中更多的并发复制作业。 但是, 由于每个工
作人员都会消耗一定数量的网络/CPU/IO资源, 请根据主机的硬件资源, 仔细选择该属性的值 - customize_crt: (on或off。 默认为on) 当此属性打开时, prepare脚本将为注册表的令牌的生成/验证创
建私钥和根证书 - ssl_cert: SSL证书的路径, 仅当协议设置为https时才应用
- ssl_cert_key: SSL密钥的路径, 仅当协议设置为https时才应用
- secretkey_path: 用于在复制策略中加密或解密远程注册表的密码的密钥路径
收尾,修改各个节点的host
1 | echo "192.168.66.100 hub.null.com" >> /etc/hosts |
另外,如果需要Windows实体机访问虚拟机中的内容,需要修改Windows实体机中的host文件,host具体路径在:C:\Windows\System32\drivers\etc\HOST,到最后追加如下内容:
1 | 192.168.66.100 hub.null.com |
打开Windows实体机中浏览器,进入网址hub.null.com即可进入harbor的后台(默认密码为admin,密码为Harbor12345)
资源清单
资源类型
k8s中的资源
K8s中所有的内容都抽象为资源,资源实例化之后,叫做对象
名称空间级别:尽在此名称空间下生效,如kube-system名称空间
- 工作负载型资源(workload):Pod、 ReplicaSet、 Deployment、 StatefulSet、 DaemonSet、Job、 CronJob( Replication Controller在v1.11版本被废弃)
- 服务发现及负载均衡型资源( ServiceDiscovery LoadBalance):Service、 Ingress…
- 配置与存储型资源:Volume(存储卷)、CSI(容器存储接口,可以扩展各种各样的第三方存储卷)
- 特殊类型的存储卷:ConfigMap(当配置中心来使用的资源类型)、 Secret(保存敏感数据)、 DownwardAPI(把外部环境中的信息输出给容器)
集群级别:Namespace、Node、Role、 ClusterRole、 RoleBinding、 ClusterRoleBinding
元数据级别:HPA、 PodTemplate、 LimitRange
常用检测命令
清理工作:
1 | #删除default命名空间下的所有pod |
检测:
1 | #获取pod状态 |
资源清单yaml格式
在k8s中,一般使用yaml格式的文件来创建符合我们预期期望的pod,这样的yaml文件我们一般称为资源清单
yaml语法:
是一个可读性高,用来表达数据序列的格式。YAML的意思其实是:仍是一种标记语言,但为了强调这种语言以数居做为中心,而不是以标记语言为重点
规则:
- 缩进时不允许使用Tab键,只允许使用空格
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- #标识注释,从这个宇符一直到行尾,都会被解释器忽略
支持的数据结构:
对象:键值对的集合,又称为映射( mapping)/哈希( hashes)/字典( dictionary)
2
3
4
age: 18
#Yaml也允许另一种写法,将所有键值对写成一个行内对象
hash: {name: Steve, age: 18}数组:一组按次序排列的值,又称为序列( sequence)/列表(list)
2
3
4
5
6
animal
- Cat
- Dog
#也可以采用行内表示法
animal: [Cat, Dog]复合结构:对象和数组可以结合使用,形成复合结构
2
3
4
5
6
7
8
9
- Ruby
- Perl
- Python
websites:
YAML: yaml.org
Ruby: ruby-lang.org
Python: python.org
Perl: use.perl.org纯量( scalars):单个的、不可再分的值(字符串、布尔值、整数、浮点数、Null、时间、日期)
2
3
4
5
6
7
8
9
10
11
12
13
number: 12.30
# 布尔值用true和 false表示
isSet: true
# null用 ~ 表示
parent: ~
# 时间采用ISO8601格式
iso8601: 2001-12-14t21:59:43.10-05:00
# 日期采用复合iso8601格式的年、月、日表示
date: 1976-07-31
# YAML允许使用两个感叹号,强制转换数据类型
e: !!str 123
f: !!str true
字符串相关说明:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
str: 这是一行字符串
# 如果字符串之中包含空格或特殊字符,需要放在引号之中
str: '内容: 字符串'
# 单引号和双引号都可以使用,双引号不会对特殊字符转义
s1: '内容\n字符串'
s2: "内容\n字符串"
# 单引号之中如果还有单引号,必须连续使用两个单引号转义
str: 'labor''s day'
# 字符串可以写成多行,从第二行开始,必须有一个缩进,换行符会被转为 空格
str: 这是一段
多行
字符串
# 多行字符串可以使用|保留换行符,也可以使用>折叠换行
this: |
Foo
Bar
that: >
Foo
Bar
# +表示保留文字块末尾的换行,-表示删除字符串末尾的换行
s1: |
Foo
s2: |+
Foo
s3: |-
Foo
常用字段解释说明
必须存在的属性:
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| version | String | 指的是K8S APl的版本,目前基本上是v1,可以用kubectl api-versions命令查询 |
| kind | String | 指的是yaml文件定义的资源类型和角色,比如:Pod |
| metadata | Object | 元数据对象,固定值就写metadata |
| metadata.name | String | 元数据对象的名字,这里由我们编写,比如命名Pod的名字 |
| metadata.namespace | String | 元数据对象的命名空间,由我们自身定义(默认为default空间) |
| Spec | Object | 详细定义对象,固定值就写Spec |
| spec.containers[] | list | Spec对象的容器列表定义,是个列表 |
| spec.containers[].name | String | 定义容器的名字(可以不填,由系统随机) |
| spec.containers[].image | String | 定义要用到的镜像名称 |
主要对象(可以不填):
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| spec.containers[].name | String | 定义容器的名字(可以不填,由系统随机) |
| spec.containers[].imagePullPollcy | String | 定义镜像拉取策略,有 Always、 Never、IfNotPresent三个值可选(1) Always:意思是每次都尝试重新(从远程)拉取镜像(2) Never:表示仅使用本地镜像(3) IfNotPresent:如果本地有镜像就使用本地镜像,没有就拉取在线镜像.(默认是 Always) |
| spec.containers[].command[] | list | 指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令 |
| spec.containers[].args[] | list | 指定容器启动命令参数,因为是数组可以指定多个 |
| spec.containers[].workingDir | String | 指定容器运行时所处的工作目录 |
| spec.containers[].volumeMounts[] | List | 指定容器内部的存储卷配置 |
| spec containers[].volumeMounts[].name | String | 指可以被容器挂载的存储卷的名称 |
| spec.containers[].volumeMounts[].mountPath | String | 指定可以被容器挂载的存储卷的路径 |
| spec.containers[].volumeMounts[].readOnly | String | 设置存储卷路径的读写模式,ture或者false默认为读写模式 |
| spec.containers[].ports[] | List | 指定容器需要用到的端口列表 |
| spec.containets[].ports[].name | String | 指定端口名称 |
| spec.containers[].ports[].containerPort | String | 指定容器需要监听的端口号 |
| spec.containers[].ports[].hostPort | String | 指定容器所在主机需要监听的端口号,默认跟上面 containerPort相同,注意设置了 hostPort,同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) |
| spec.containers[].ports[].protocol | String | 指定端口协议,支持TCP和UDP,默认值为TCP |
| spec.containers[].env[] | List | 指定容器运行前需设置的环境变量列表 |
| spec.containersl].env[].name | String | 指定环境变量名称 |
| spec.containers[].env[].value | String | 指定环境变量值 |
| spec.containers[].resources | Object | 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) |
| spec.containers[].resources.limits | Object | 指定设置容器运行时资源的运行上限 |
| spec.containers[].resources.limits.cpu | String | 指定CPU的限制,单位为core数,将用于docker run --cpu-shares参数(这里前面文章Pod资源限制有讲过) |
| spec.containers[].resources.limits.memory | String | 指定MEM内存的限制,单位为MIB、GiB |
| spec.containers[].resources.requests | Object | 指定容器启动和调度时的限制设置 |
| spec.containers[].resources.requests.cpu | String | CPU请求,单位为core数,容器启动时初始化可用数量 |
| spec.containers[].resources.requests.memory | String | 内存请求,单位为MIB、GiB,容器启动的初始化可用数量 |
额外的参数项:
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| spec.restartPolicy | String | 定义Pod的重启策略,可选值为 Always、 OnFailure,默认值为 Always. 1Always:pod一旦终止运行,则无论容器是如何终止的, kubelet服务都将重启它。2.OnFailure:只有pod以非零退出码终止时, kubelet会重启该容器。如果容器正常结束(退出码为0),则 kubelet将不会重启它 3. Never:pod终止后, kubeletMast将退出码报告给,不会重启该 Pod. |
| spec.nodeSelector | Object | 定义node的Label过滤标签,以key:value格式指定 |
| spec.imagePullSecrets | Object | 定义pull镜像时secret使用名称,以 name:secretkey格式指定 |
| spec.hostNetwork | Boolean | 定义是否使用主机网络模式,默认值为fase.设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机上启动第二个副本。 |
其他具体的可以通过如下命令查询:
1 | kubectl explain <资源类型> |
最简单的模板:
1 | apiVersion: v1 |
-
编写后如果有错误,可以尝试从以下方面着手解决:
1
2
3
4#查看pod内部信息
kubectl describe pod pod名字
# 查看对应报错容器日志(通过-c指定多个容器中的一个,若pod中只有一个容器则无需指定)
kubectl log pod名字 -c 容器名字
容器生命周期
pod的基本的生命周期如下所示:
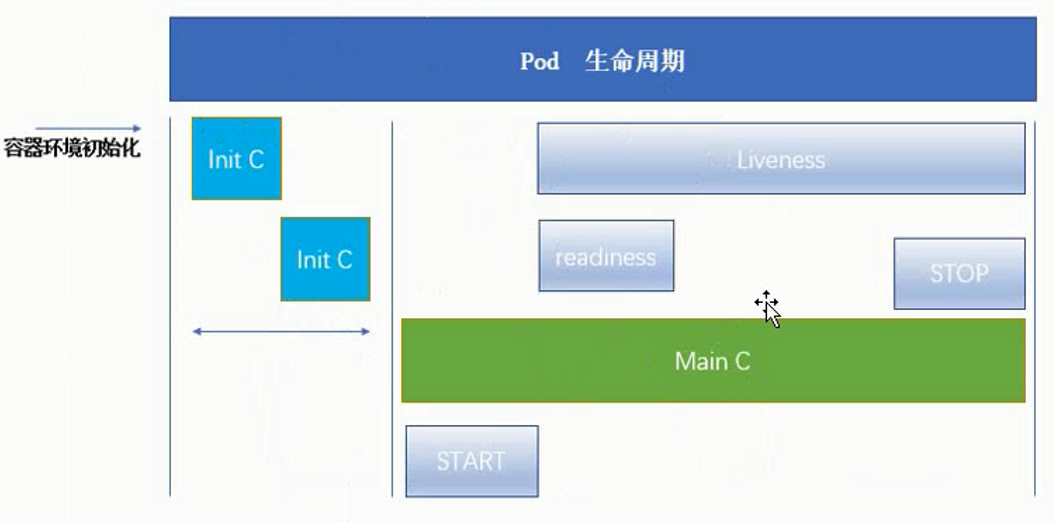
- kubectl先kubeapi发送调度指令,kubeapi会调度kubelet,整个调度过程中间由etcd在中间完成,包括存储及其他功能。
- kubelet会操作CRI去完成容器的初始化
- 初始化过程中会先启动pause的基础容器,负责网络以及存储资源的共享
- pause负责多个(或者0个)Init C(compose)的初始化
- Init C如果非正常退出(退出码为非0),会根据重启策略判断是否重新执行
- 这些Init C不是并行的
- Init C初始化完成后,会进入Main C(compose)中运行
- Main C在刚运行的时候,可以启动START脚本/命令,同样,在结束的时候也可以执行STOP脚本/命令
- Main C的执行过程中会有readiness和Liveness的参与
- readiness可以根据配置在Main C开始执行的一定时间后启动,负责就绪检测,如果检测成功后Pod的状态会变成Running或Ready
- Liveness可以根据配置在Main C开始执行的一定时间后启动,会伴随着Main C的整个生命周期,负责检测Main C中的进程,如果发现有不正常的现象,会根据重启策略执行诸如重启、删除pod等命令
Init C
Pod能够具有多个容器,应用运行在容器里面,但是它也可能有一个或多个先于应用容器启动的Init容器。Init容器与普通的容器非常像,除了如下两点:
- Init容器总是运行到成功完成为止
- 每个Init容器都必须在下一个Init容器启动之前成功完成
如果Pod的Init容器失败, Kubernetes会不断地重启该Pod,直到Init容器成功为止。然而,如果Pod对应的 restartPolicy(重启策略)为 Never,它不会重新启动
因为Init容器具有与应用程序容器分离的单独镜像,所以它们具有如下优势:
- 它们(Init容器)可以包含并运行实用工具,但是出于安全考虑,是不建议在应用程序容器镜像中包含这些实用工具的
- 它们(Init容器)可以包含使用工具和定制化代码来安装,但是不能出现在应用程序镜像中。例如,创建镜像没必要FROM另一个镜像,只需要在安装过程中使用类似sed、awk、 python或dig这样的工具
- 应用程序镜像可以分离出创建和部署的角色,而没有必要联合它们构建一个单独的镜像。
- Init容器使用 Linux Namespace,所以相对应用程序容器来说具有不同的文件系统视图。因此,它们能够具有访问 Secret的权限,而应用程序容器则不能
- 它们(Init容器)必须在应用程序容器启动之前运行完成,而应用程序容器是并行运行的,所以Init容器能够提供了一种简单的阻塞或延迟应用容器的启动的方法,直到满足了一组先决条件。
Init C模板:
1 | apiVersion: v1 |
想要上诉代码成功的通过Init C,需要有以下两个服务被创建:
1 | kind: Service |
特殊说明:
- 在Pod启动过程中,Init容器会按顺序在网络和数据卷初始化(这两个都是在pause中完成的)之后启动。每个容器必须在下一个容器启动之前成功退出
- 如果由于运行时或失败退出,将导致容器启动失败,它会根据Pod的 restartPolicy指定的策略进行重试。如果Pod的 restartPolicy设置为 Always,Init容器失败时会使用RestartPolicy策略(即重新初始化)
- 在所有的Init容器没有成功之前,Pod将不会变成 Ready状态。Init容器的端口将不会在Service中进行聚集。正在初始化中的Pod处于 Pending状态,但应该会将 Initializing状态设置为true
- 如果Pod重启,所有Init容器必须重新执行
- pod启动后,如果对Init容器spec的修改,范围会被限制在容器 image字段,修改其他字段都不会生效。更改Init容器的 Image字段,等价于重启该Pod
- Init容器具有应用容器的所有字段,除了 readinessProbe字段(就绪检测)。因为Init容器无法定义不同于完成( completion)的就绪( readiness)之外的其他状态。
- 在Pod中的每个app和Init容器的名称必须唯一;与任何其它容器共享同一个名称,会在验证时抛出错误
- Init C中端口可以冲突
探针
探针是由 kubelet对容器执行的定期诊断。要执行诊断, kubelet调用由容器实现的 Handler。Handler有三种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为0则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的IP地址进行TCP检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的IP地址执行 Http Get请求。如果响应的状态码大于等于200且小于400,则诊断被认为是成功的
每次探测都将获得以下三种结果之一
- 成功:容器通过了诊断
- 失败:容器未通过诊断
- 未知:诊断失败,因此不会采取任何行动
探测方法:
- livenessProbe:存活探测,指示容器是否正在运行。如果存活探测失败,则 kubelet会杀死容器(Main C),并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为 Success
- readinessProbe:就绪探测,指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与Pod匹配的所有 Service的端点中删除该Pod的IP地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success
例子1(readinessprobe-httpget):
1 | apiVersion: v1 |
例子2(livenessProbe-exec):
1 | apiVersion: v1 |
例子3(livenessProbe-httpget):
1 | apiVersion: v1 |
例子4(livenessProbe-tcp):
1 | apiVersion: v1 |
start、stop、相位
启动退出动作模板:
1 | apiVersion: v1 |
Pod的 status字段是一个 Podstatus对象, PodStatus中有一个 phase(相位)字段。该字段是Pod在其生命周期中的简单宏观概述。该阶段并不是对容器或Pod的综合汇总,也不是为了作为综合状态机。Pod相位的数量和含义是严格指定的。除了下面列举的状态外,不应该再假定Pod有其他的phase值:
- 挂起( Pending):Pod已被 Kubernetes系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度Pod的时间和通过网络下载镜像的时间,这可能需要花点时间
- 运行中( Running):该Pod已经绑定到了一个节点上,Pod中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态
- 成功( Succeeded):Pod中的所有容器都被成功终止(每个pod的退出码为0,即正常退出),并且不会再重启
- 失败( Failed):Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止
- 未知( Unknown):因为某些原因无法取得Pod的状态,通常是因为与Pod所在主机通信失败
资源控制器
相关模板及帮助文档均可通过以下命令查询:
1 | kubectl explain <资源类型> |
Pod 的分类:
- 自主式 Pod:Pod 退出了,此类型的 Pod 不会被创建
- 控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
控制器:Kubernetes中内建了很多 controller(控制器),这些相当于一个状态机,用来控制Pod的具体状态和行为
控制器类型:
- ReplicationController和ReplicaSet
- Deployment
- DaemonSet
- StateFulSet
- Job/CronJob
- Horizontal Pod Autoscaling
ReplicationController和ReplicaSet
ReplicationController(RC)用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收;
在新版本的Kubernetes中建议使用ReplicaSet 来取代 ReplicationController。ReplicaSet跟ReplicationController没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector(通过标签控制)
模板:
1 | apiVersion: extensions/v1beta1 |
Deployment
Deployment为Pod和Replicaset提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationController来方便的管理应用。典型的应用场景包括;
命令式编程:侧重于如何实现程序,就像我们刚接触编程的时候那样,我们需要把程序的实现过程按照逻辑结果一步步写下来
声明式编程:侧重于定义想要什么,然后告诉计算机/引擎,让他帮你去实现
- 通过定义Deployment来创建Pod和Replicaset(Deployment会创建ReplicaSet进而创建Pod)
- 滚动升级和回滚应用(会保留之前版本的ReplicaSet)
- 扩容和缩容
- 暂停和继续Deployment
模板:
1 | apiVersion: extensions/v1beta1 |
相关示例:
yaml文件为上述模板
1 | kubectl create -f nginx-deployment.yaml --record ##--record:记录命令,可以方便查看每次revision的变化 |
细节知识
Rollover
假如您创建了一个有5个niginx:1.7.9 replica的 Deployment,但是当还只有3个nginx:1.7.9的 replica 创建出来的时候就开始更新含有5个 nginx:1.9.1 replica 的 Deployment。在这种情况下,Deployment 会立即杀掉已创建的3个nginx:1.7.9的Pod,并开始创建nginx:1.9.1的 Pod。不会等到所有的5个nginx:1.7.9的Pod都创建完成后才开始改变航道
回退相关命令(接上述 相关示例 )
1 | kubectl set image deployment/nginx-deployment nginx=nginx:1.91 # 更新镜像 |
可以通过设置.spec.revisonHistoryLimit项来指定 deployment 最多保留多少 revision 历史记录。默认的会保留所有的 revision;如果将该项设置为0,Deployment 将不允许回退
Daemonset
DaemonSet 确保全部(或者一些)Node上运行一个Pod的副本。当有Node加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod。使用Daemonset的一些典型用法:
- 运行集群存储daemon,例如在每个Node 上运行glusterd、ceph
- 在每个Node 上运行日志收集daemon,例如fluentd、logstash
- 在每个Node 上运行监控daemon,例如Prometheus Node Exporter、collectd、Datadog 代理、New Relic 代理,或Ganglia gmond
实例:
1 | apiVersion: apps/v1 |
Job
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束
Job Spec
.spec.completions标志Job结束需要成功运行的Pod个数,默认为1
.spec.parallelism标志并行运行的Pod的个数,默认为1
.spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
例子:
1 | apiversion: batch/v1 |
命令:
1 | kubectl create -f xxxx.yaml |
CronJob
CronJob管理基于时间的Job(与Deployment类似,本质是在特定的时间循环创建Job),即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
使用前提条件:当前使用的Kubernetes集群版本>= 1.8 (对CronJob)。
典型的用法如下所示:
- 在给定的时间点调度Job运行
- 创建周期性运行的Job,例如:数据库备份、发送邮件
CronJob Spec
.spec.schedule:调度,必需字段,指定任务运行周期,格式同Cron
.spec.jobTemplate:Job模板,必需字段,指定需要运行的任务,格式同Job
.spec.startingDeadlineSeconds:启动Job的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的Job将被认为是失败的。如果没有指定,则没有期限
.spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被CronJob创建的Job的并发执行。只允许指定下面策略中的一种:
-
Allow(默认):允许并发运行Job -
Forbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个 -
Replace:取消当前正在运行的Job,用一个新的来替换注意,当前策略只能应用于同一个CronJob创建的Job。如果存在多个CronJob,它们创建的Job之间总是允许并发运行。
.spec.suspend:挂起,该字段也是可选的。如果设置为true,后续所有执行都会被挂起。它对已经开始执行的Job不起作用。默认值为false。
.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit:历史限制,是可选的字段。它们指定了可以保留多少完成和失败的Job。默认情况下,它们分别设置为3和1。设置限制的值为0,相关类型的Job完成后将不会被保留。
例子:
1 | apiversion: batch/v1beta1 |
限制
- 创建Job操作应该是幂等的
- 成功与否并不太好去判断(但是Job可以判断)
StatefulSet
StatefulSet作为Controller 为Pod提供唯一的标识。 它可以保证部署和scale的顺序。StatefulSet是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service (即没有Cluster IP的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
- 有序收缩,有序删除(即从N-1到0)
Horizontal Pod Autoscaling
应用的资源使用率通常都有高峰和低谷的时候,如何削峰填谷,提高集群的整体资源利用率,让service中的Pod个数自动调整?这就有赖于Horizontal Pod Autoscaling了,顾名思义,使Pod水平自动缩放
HPA(Horizontal Pod Autoscaling)可以理解为是一个控制器的附属品,在选定其他控制器后再来确定是否需要HPA来管理选定的其他控制器。HPA可以根据K8s的一些资源指标(如CPU使用情况等)来对Pod进行水平缩放