
python爬虫
定向网络数据爬取和网页解析
request库:http://www.python-request.org
requests库官方文档中文版:http://cn.python-requests.org/zh_CN/latest/index.html
BeautifulSoup库官方文档中文版:http://beautifulsoup.readthedocs.io/zh_CN/latest/
PEP8——Python代码规范:https://www.python.org/dev/peps/pep-0008/
简单入门:
1 | import request |
常用的7个方法:
1 | requests.request()#构造一个请求,支撑以下各方法的基础方法 |
- 实际上底层都是使用了
request方法来封装
爬虫的尺寸:
- Requests库:小规模,数据量小,爬取速度不敏感(爬取网页 玩转网页)
- Scrapy库:中规模,数据规模较大,爬取速度敏感(爬取网站 爬取系列网站)
- 定制开发:大规模,搜索引擎,爬取速度关键(爬取全网)
get
1 | r = request.get(url) |
- get方法构造一个向服务器请求资源的Request对象(由request库内部生成)
- r:返回一个包含服务器资源的Response对象(包括从服务器返回的所有资源)
- url:拟获取页面的url链接
- params:url中的额外参数,字典或字节流格式,可选
- **kwargs:12个控制访问的参数
Response对象常用属性:
r.status_code:HTTP请求的返回状态,200表示连接成功,404表示失败(其余各种数均为失败)r.text:HTTP响应内容的字符串形式,即,url应的页面内容r.encoding:从 HTTP header中猜测的响应内容编码方式(如果HTTP header中不存在,则默认为ISO-8859-1)r.apparent_encoding:从内容中分析出的响应内容编码方式(备选编码方式)r.content:HTTP响应内容的二进制形式(保存图片可能会用到)
通用代码框架
request库的相关异常:
requests.ConnectionError:网络连接错误异常,如DNS查询失败、拒绝连接等requests.HTTPError:HTTP错误异常requests.URLRequired:URL缺失异常requests.TooManyRedirects:超过最大重定向次数,产生重定向异常requests.ConnectTimeout:连接远程服务器超时异常(仅仅指与远程服务器连接的时间)requests.Timeout:请求URL超时,产生超时异常(发出请求到获得内容的整个过程的时间)
产生异常函数:
1 | r.raise_for_status()#如果不是200,产生异常requests.HTTPError |
通用代码框架:
1 | import requests |
HTTP协议及request库方法
HTTP协议
HTTP, Hypertext Transfer Protocol,超文本传输协议,基于"请求与响应"模式的、无状态的应用层协议,采用URL作为定位网络资源的标识。URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
URL格式:http://host[:port][path]
- host:合法的 Internet主机域名或IP地址
- port:端口号,缺省端囗为80
- path:请求资源的路径
HTTP协议对资源的操作:
GET:请求获取URL位置的资源HEAD:请求获取URL位置资源的响应消息报告,即获得该资源的头部信息POST:请求向URL位置的资源后附加新的数据PUT:请求向URL位置存储一个资源,覆盖原URL位置的资源PATCH:请求局部更新URL位置的资原,即改变该处资原的部分内容(节省网络带宽)DELETE:请求删除URL位置存储的资源
注:上述方法和request库中的方法是一一对应的
request库方法
由于网络安全的限制,一般只会使用到get,对于某些特别大的url链接只用head即可
request方法:所有方法的基础方法
1 | requests.request(method, url, **kwargs) |
-
method:请求方式,对应其他get/put/post等7种方法
1
2
3
4
5
6
7requests.request('GET', url, **kwargs)
requests.request('HEAD', url, **kwargs)
requests.request('POST', url, **kwargs)
requests.request('PUT', url, **kwargs)
requests.request('PATCH', url, **kwargs)
requests.request('delete', url, **kwargs)
requests.request('OPTIONS', url, **kwargs) -
url:拟获取页面的url链接
-
**kwargs:控制访问的参数,共13个
-
params:字典或字节序列,作为参数增加到url中
1
2
3
4
5
6kv = {'key1':'value1','key2':'value2'}
r = requests.request('GET','http://python123.io/ws',params = kv)
print(r.url)
https://python123.io/ws?key1=value1&key2=value2
print(r.request.url)#发过去的链接
https://python123.io/ws?key1=value1&key2=value2 -
data:字典、字节序列或文件对象,作为 Request的内容
1
2
3
4kv = {'key1':'value1','key2':'value2'}
r = requests.request('POST','http://python123.io/ws',data = kv)
body = '主体内容'
r = requests.request('POST','http://python123.io/ws',data = body) -
json:JSON格式的数据,作为 Request的内容
1
2kv = {'key1':'value1'}
r = requests.request('POST','http://python123.io/ws',json = kv)#赋值到服务器的json域上 -
headers:字典,HTTP定制头
1
2hd = {'user-agent':'Chrome/10'}
r = requests.request('POST','http://python123.io/ws',headers = hd) -
cookies:字典或 Cookiejar, Request中的 cookie
-
auth:元组,支持HTTP认证功能
-
files:字典类型,传输文件
1
2fs = {'file':open('data.xls','rb')}
r = requests.request('POST','http://python123.io/ws',files = fs) -
timeout:设定超时时间,秒为单位(如果请求内容没有返回回来,会产生一个超时的异常)
1
r = requests.request('GET','http://www.baidu.com',timeout = 10)
-
proxies:字典类型,设定访问代理服务器,可以增加登录认证
1
2pxs = {'http':'http://user:pass@10.10.10.1:1234','https':'https://10.10.10.1:4321'}#增加http和https的代理,防止对爬虫的逆追踪
r = requests.request('GET','http://www.baidu.com',proxies = pxs) -
allow_redirects:True/ False,默认为True,重定向开关
-
stream:True/ False,默认为True,获取内容立即下载开关
-
verify:True/ False,默认为True,认证SSL证书开关
-
cert:本地SSL证书路径
-
get方法:获取网页
1 | requests.get(url, params=None, **kwargs) |
- url:拟获取页面的url链接
- params:url中的额外参数,字典或字节流格式,可选
- **kwargs:12个控制访问的参数(request方法中除了params的12个访问参数)
head方法:用很少的流量获得资源的概要信息
1 | requests.head(url, **kwargs) |
- url:拟获取页面的url链接
- **kwargs:13个控制访问的参数(与request方法中一样)
例子:
1 | r = requests.head('http://httpbin.org/get') |
post方法:向服务器提交新增数据。向 URL POST一个字典会自动编码为form(表单),向 URL POST一个字符串会自动编码为data
1 | requests.post(url, data=None, json=None, **kwargs) |
- url:拟获取页面的url链接
- data:字典、字节序列或文件, Request的内容
- json:JSON格式的数据, Request的内容
- **kwargs:剩下11个控制访问的参数(与request方法中一样)
例子:
1 | payload = {'key1':'value1','key2':'value2'} |
put方法:与post方法类似,只不过会覆盖原有数据
1 | requests.put(url, data=None, **kwargs) |
- url:拟获取页面的url链接
- data:字典、字节序列或文件, Request的内容
- **kwargs:剩下12个控制访问的参数(与request方法中一样)
patch方法:向HTML网页提交局部修改请求,对应于HTTP的PATCH,能够节省网络带宽
1 | requests.patch(url, data=None, **kwargs) |
- url:拟获取页面的url链接
- data:字典、字节序列或文件, Request的内容
- **kwargs:剩下12个控制访问的参数(与request方法中一样)
delete方法:
1 | requests.patch(url, **kwargs) |
- url:拟获取页面的url链接
- **kwargs:13个控制访问的参数(与request方法中一样)
Robots协议
一些网站对网络爬虫的限制:
- 来源审查:判断 User-Agent进行限制
- 检查来访HTTP协议头的User-Agent域或,只响应浏览器或友好爬虫的访问
- 发布公告: Robots协议,Robots exclusion standard 网络爬虫排除标准
- 告知所有爬虫,网站的爬取策略,要求爬虫遵守.
Robots协议:
- 作用:网站告知网络爬虫哪些页面可以抓取,哪些不行
- 形式:在网站根目录下的 robots.txt文件中写明了那些目录能够爬取,那些不能
例子(京东Robots协议https://www.jd.com/robots.txt):
1 | User-agent: * |
User-agent: *:对于任何的爬虫来源,都应该遵守如下规则Disallow:不允许访问的目录和文件EtaoSpider、HuihuiSpider、GwdangSpider、WochachaSpider:对这四类爬虫禁止爬取
其他例子:
- 百度:http://www.baudu.com/robots.txt
- 新浪:http://www.sina.com.cn/robots.txt
- QQ:http://www.qq.com/robots.txt
- QQ新闻:http://news.qq.com/robots.txt
遵守方式
要求网络爬虫能够自动或人工识别 robots.txt,再进行内容爬取
Robots协议是建议但非约束性,网络爬虫可以不遵守,但存在法律风险.
实例
亚马逊商品获取:
1 | import requests |
360、百度的搜索:
1 | import requests |
网络图片的爬取和存储:
1 | import requests |
网络爬虫与信息提取
BeautifulSoup库:能够解析HTML和XML
BeautifulSoup库官方文档中文版:http://beautifulsoup.readthedocs.io/zh_CN/latest/
BeautifulSoup库的基本元素
HTML/XML文档 <==> 标签树 <==> BeautifulSoup类,即BeautifulSoup类对应一个 HTMLIXML文档的全部内容.
1 | #常用形式: |
BeautifulSoup库的解析器:
- bs4的HTML解析器:
BeautifulSoup( mk, 'html.parser'),需要安装bs4库 - lxml的HTML解析器:
BeautifulSoup(mk,'lxml'),需要安装lxml:
pip install Ixml - lxml的XML解析器:
BeautifulSoup(mk, ‘xml’),需要安装lxml:pip install lxml - htmI5lib的解析器:
BeautifulSoup(mk, 'html5lib'),需要安装html5lib:pip install html5lib
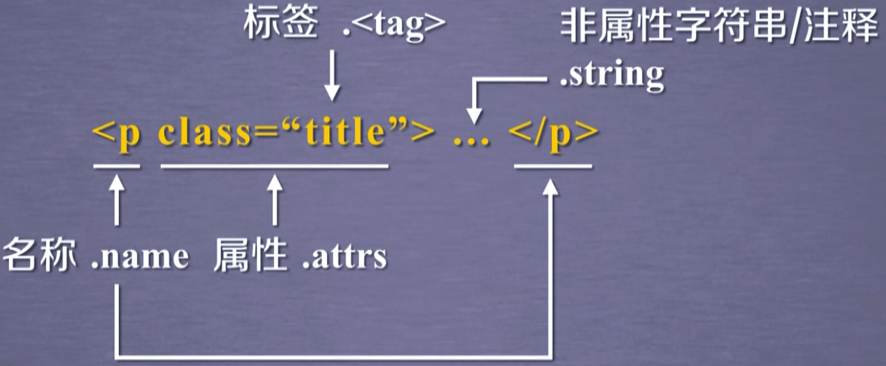
BeautifulSoup类的基本元素:
Tag:标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾Name:标签的名字,…
的名字是’p’,格式:.name Attributes:标签的属性,字典形式组织,格式:.attrs - 无论标签有没有属性,总能获得一个attrs,无属性就是空
NavigableString:标签内非属性字符串,<>…</>中字符串,格式:.string Comment:标签内字符串的注释部分,一种特殊的Comment类型
例子:
对于如下demo网页https://python123.io/ws/demo.html,其内容为:
1 | <html> |
使用方法:
1 | import requests |
关于注释的例子:
1 | from bs4 import BeautifulSoup |
- 是字符串还是注释,需要根据类型去判断
HTML遍历
下行遍历:沿着根节点向叶子节点遍历的
上行遍历:沿着叶子结点向根节点遍历
平行遍历:在平行节点之间互相遍历
标签树的下行遍历:
.contents:子节点的列表,将所有儿子节点存入列表 .children:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点.descendants:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
例子:
1 | from bs4 import BeautifulSoup |
- 一个标签的子节点并不仅仅只有标签节点,也存在字符串节点,如:‘\n’
标签树的上行遍历:
.parent:节点的父亲标签.parents:节点先辈标签的迭代类型,用于循环遍历先辈节点
例子:
1 | from bs4 import BeautifulSoup |
标签树的平行遍历:
- .next_sibling:返回按照HTML文本顺序的下一个平行节点标签
- .previous_sibling:返回按照HTML文本顺序的上一个平行节点标签
- .next_siblings:迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
- .previous_siblings:迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
条件:所有的平行遍历都发生在同一个父节点下的各节点间
注意:任何一个节点的平行、父亲、儿子节点是可能存在NavigableString类型的
例子:
1 | from bs4 import BeautifulSoup |
HTML格式化和编码
基于bs4库的prettify()方法
例子:
1 | from bs4 import BeautifulSoup |
bs4将任何html文件或字符串都转化为了utf-8编码
信息标记
信息标记的三种形式:
-
XML(eXtensible Markup Language):采取了以标签为主,来构建信息表达信息的方式(XML是HTML发展以来的一种通用信息表达形式)
- 在标签中具有名字、属性,与HTML类似:
<img src="china,jpg" size="10">...</img> - 如果标签中没有内容,可以采用缩写形式:
<img src="china,jpg" size="10" /> - 可以嵌入注释:
<!--This is acomment, very useful -->
- 在标签中具有名字、属性,与HTML类似:
-
JSON(JavsScript Object Notation):有类型的键值对构建的信息表达方式
- 规定:
- 键:对信息类型进行定义
- 值:对信息值的描述
- 键值对具有数据类型:无论是键还是值,均需要通过
"来表示字符串 - 当值中有多个信息的时候,采用
[,]形式来组织:"name":["北京","延安"] - 键值对之间可以嵌套使用,嵌套时采用
{,}书写:"name":{"oldname":"北京","newname":"延安"}
- 好处:
- 对于JavaScript等编程语言来说,可以直接将JSON作为程序的一部分
- 规定:
-
YAML(YAML Aint Markup Language):采用无类型键值对,在键值之间不采用任何双引号或相关的类型标记
-
没有数据类型:
name:北京 -
可以通过缩进的关系表达所属关系
-
用
-表达并联关系 -
用
|表示整块数据 -
用
#表示注释1
2
3
4
5
6key : value
key : #Comment
-value1
-value2
key :
dubkey : subvalue
-
对比:
- XML最早的通用信息标记语言,可扩展性好,但繁琐.
- Internet上的信息交互和传递
- JSON信息有类型,适合程序处理(js),较XML简洁.
- 移动应用云端和节点的信息通信,无注释.
- YAML信息无类型,文本信息比例最高,可读性好.
- 各类系统的配置文件,有注释易读.
信息提取的一般方法:
- 完成解析信息的标记形式,再提取关键信息
- 优点:信息解析准确
- 缺点:提取过程繁琐,速度慢
- 无视标记形式,直接搜索关键信息
- 优点:提取过程简洁,速度较快.
- 缺点:提取结果准确性与信息內容相关
- 融合方法:结合形式解析与搜索方法,提取关键信息
例子:
1 | #融合方法:先查找a的标签 再解析 |
内容查找
基本方法:
1 | <>.find_all(name,attrs,recursive,string,**kwargs) |
- 返回值:列表,储存查取结果
- name:对标签名称的检索字符串,如果为True则输出所有标签信息,可以使用正则表达式
- attrs:对标签属性值的检索字符串,可标注属性检索,只能够精确查找,否则需要正则表达式
- recursive:是否对子孙所有节点进行检索,默认True
- string:<>…</>中字符串区域的检索字符串,只能够精确查找,否则需要正则表达式
注意,由于find_all方法常用,可以简写为:
<tag>.find_all(...)等价于<tag>(...)soup.find_all(...)等价于soup(...)
例子:
1 | from bs4 import BeautifulSoup |
扩展方法(与find_all的参数一样):
<>.find():搜索且只返回一个结果,字符串类型,同.find_all()参数<>.find_parents():在先辈节点中搜索,返回列表类型,同.find_all()参数<>.find_parent():在先辈节点中返回一个结果,字符串类型,同.find_all()参数<>.find_next_siblings():在后续平行节点中搜索,返回列表类型,同.find_all()参数<>.find_next_sibling():在后续平行节点中返回一个结果,字符串类型,同.find_all()参数<>.find_previous_siblings():在前序平行节点中搜索,返回列表类型,同.find_all()参数<>.find_previous_sibling():在前序平行节点中返回一个结果,字符串类型,同.find_all()参数
实例
中国大学排名定向爬虫
定向爬虫:仅对输入URL进行爬取,不扩展爬取.
爬取网页:http://www.zuihaodaxue.com/BCSR/xinxiyutongxingongcheng2019.html,且没有robots.txt文件
部分html代码:
1 | <tbody> |
1 | # encoding=utf-8 |
-
上述代码中,由于format输出过程中,采用英文空格填充,因为中英文间距宽度不同,所以会使得结果不会居中
-
为解决居中问题,可以将默认的填充字符由英文空格换成中文空格
ch(12288)即可 -
修改后的
printUnivList函数:1
2
3
4
5
6def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"#{3}是采用第三个参数,即中文空格chr(12288)
print(tplt.format("排名","名称","总分",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
正则表达式库
- 通用的字符串表达框架
- 用来简洁的表达一组字符串的表达式
- 是字符串表达”简洁“和”特征“思想的工具
- 判断某字符串的特征归属
正则表达式是由字符和操作符构成的
操作符
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [] | 字符集,对单个字符给出取值范围 | [abc]表示a、b、c,[a-z]表示a到z单个字符 |
| [^] | 非字符集,对单个字符给出排除范围 | [^abc]表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc*表示ab、abc、abcc、abccc等 |
| + | 前一个字符1次或无限次扩展 | abc+表示abc、abcc、abccc等 |
| ? | 前一个字符0次或1次扩展 | abc?表示abc、abcc、abccc等 |
| | | 左右表达式任意一个 | abc|def表示abc或者是def |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次(包含n) | ab{1,2}c表示abc、abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 |
| () | 分组标记,内部只能使用|操作符 | (abc)表示abc,(abc|def)表示abc或def |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符,等价于[A-Za-z0-9_] |
Match对象
一次匹配的结果,包含了很多匹配的相关信息,Match对象的具体类型为re.Match
重要属性:
.string:待匹配的文本.re:匹配时使用的 pattern对象(即正则表达式).pos:正则表达式搜索文本的开始位置.endpos:正则表达式搜索文本的结束位置
常用方法:
.group(0):获得匹配后的字符串.start():匹配字符串在原始字符串的开始位置.end():匹配字符串在原始字符串的结束位置.span():返回(.start(), .end())
例子:
1 | import re |
相关函数
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回 match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回 match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是 match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
函数说明:
1 | re.search(pattern, string, flags=0) |
在一个字符串中搜索匹配正则表达式的第一个位置,返回 match对象
- pattern:正则表达式的字符串或原生字符串表示
- 原生字符串(raw string):即
r"xxxx"类型字符串
- 原生字符串(raw string):即
- string:待匹配字符串
- flags:正则表达式使用时的控制标记
re.I(re.IGNORECASE):忽略正则表达式的大小写,[A-Z]能够匹配小写字符re.M(re.MULTILINE):正则表达式中的**^操作符能够将给定字符串的每行**当作匹配开始re.S(re.DOTALL):正则表达式中的**.操作符能够匹配所有字符**(默认匹配除换行外的所有字符)
例子:
2
3
4
5
match = re.search(r'[1-9]\d{5}','TaiAn 271035,WeiHai 264200')
if match :
print(match.group(0))
#输出 271035
1 | re.match(pattern, string, flags=0) |
从一个字符串的开始位置起匹配正则表达式,返回match对象
- 参数同
search函数
例子:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
re.match()从字符串的起始位置开始匹配,如果起始位置匹配不成功,则匹配失败
'''
import re
match = re.match(r'[1-9]\d{5}','TaiAn 271035,WeiHai 264200')
if match :
print(match.group(0))
else:
print(type(match))
#输出<class 'NoneType'>
#匹配成功例子:
match = re.match(r'[1-9]\d{5}','271035 TaiAn,WeiHai 264200')
if match :
print(match.group(0))
else:
print(type(match))
#输出 '271035'
1 | re.findall(pattern, string, flags=0) |
搜索字符串,以列表类型返回全部能匹配的子串
- 参数同
search函数
例子:
2
3
4
5
6
7
8
ls = re.findall(r'[1-9]\d{5}','TaiAn 271035 WeiHai 264200 222222 115545')
if ls :
print(ls)
else:
print(type(ls))
#['271035', '264200', '222222', '115545']注意:findall如果使用了分组,则输出的内容将是分组中的内容而非find到的结果:
2
3
4
5
6
7
xxx = "a123ca456c"
ret = re.findall(r"a(123|456)c", xxx)
print(ret)
#['123', '456']解决方法:
- 加上问号来启用“不捕捉模式”
- 不用分组
2
3
4
ret = re.findall(r"a(?:123|456)c", xxx)
#不用分组
ret = re.findall(r"a123c|a456c", xxx)
1 | re.split(pattern, string, maxsplit=0, flags=0) |
将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
- maxsplit:最大分割数,剩余部分作为最后一个元素输出
- 其余参数同
search函数
例子:
2
3
4
5
re.split(r'[1-9]\d{5}','TaiAn271035WeiHai264200wo222222nihao115545abc')
['TaiAn', 'WeiHai', 'wo', 'nihao', 'abc']
re.split(r'[1-9]\d{5}','TaiAn271035WeiHai264200wo222222nihao115545abc',maxsplit=2)
['TaiAn', 'WeiHai', 'wo222222nihao115545abc']
1 | re.finditer(pattern, string, flags=0) |
搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是 match对象
- 参数同
search函数
例子:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
for m in re.finditer(r'[1-9]\d{5}','TaiAn271035WeiHai264200wo222222nihao115545abc') :
if m:
print(m.group(0))
print(type(m))
else:
print("null")
...
271035
<class 're.Match'>
264200
<class 're.Match'>
222222
<class 're.Match'>
115545
<class 're.Match'>
1 | re.sub(pattern, repl, string, count=0, flags=0) |
用一个新的字符串替换所有匹配正则表达式的子串,返回替换后的字符串
- repl:替换匹配字符串的字符串
- count:匹配的最大替换次数
- 其余参数同
search函数
例子:
2
3
re.sub(r'[1-9]\d{5}','隐藏邮政编码','TaiAn271035WeiHai264200wo222222nihao115545abc')
'TaiAn隐藏邮政编码WeiHai隐藏邮政编码wo隐藏邮政编码nihao隐藏邮政编码abc'
等价用法
-
函数式用法:一次性操作
1
rst = re.search(r'[1-9]\d{5}','BIT 100081')
-
面向对象用法:编译后的多次操作(能够加快程序运行速度)
1
2pat = re.compile(r'[1-9]\d{5}')
rst = pat.search('BIT 100081')
compile函数:
1 | regex = re.compile(pattern, flags=0) |
将正则表达式的字符串形式编译成正则表达式对象
- pattern:正则表达式的字符串或原生字符串表示
- flags:正则表达式使用时的控制标记
注意:这里regex才是正则表达式(对象),代表了一组字符串。同时regex对象也含有上述re库提供的的六个方法,但是需要将方法中的pattern参数去除
贪婪匹配和最小匹配
Re库默认釆用贪婪匹配,即输出匹配最长的子串
例子:
1 | import re |
最小匹配:输出匹配最短的子串,具体方法为 在匹配不同长度的操作符后 加个?即可
具体扩展的操作符:
| 操作符 | 说明 |
|---|---|
| *? | 前一个字符0次或无限次扩展,最小匹配 |
| +? | 前一个字符1次或无限次扩展,最小匹配 |
| ?? | 前一个字符0次或1次扩展,最小匹配 |
| {m,n}? | 扩展前一个字符m至n次(含n),最小匹配 |
例子:
1 | import re |
实例
淘宝商品价格爬取
搜索接口:https://s.taobao.com/search?q=篮球
翻页接口:第二页 https://s.taobao.com/search?q=篮球&s=44
第三页 https://s.taobao.com/search?q=篮球&s=88
用爬虫爬淘宝,得到的页面是登录页面,想要跳过这个页面,需要提前在浏览器中登录淘宝,并获取hearders信息(关键是cookie和User-Agent)用于模拟用户登录,并作为参数传给requests.get(url,headers = header),获取方法如下:
首先登陆淘宝账号,然后按 F12 进入检查,在上面的 network 的第一行中拖到最后,找到最上方以search?开头的一栏,右键 Copy–>Copy as URL(bash),然后打开这个网站: https://curl.trillworks.com/ 在里面把复制的内容放进去,选择 Python 然后会发现右边有一个 headers:{省略…},把这个 headers 放进代码,用一个变量储存,然后在代码中的r equest.get(url,headers=你刚才复制的内容,也就是那个变量),这个时候你再请求 request.text 返回的就是你要的页面
1 | import requests |
股票数据定向爬取:
步骤1:从中财网http://quote.cfi.cn/stockList.aspx获取股票列表
步骤2:根据股票列表获取股票的url,通过每个url获取股票信息
步骤3:将结果保存到文件中
1 | #股票数据定向爬虫 |
Scrapy框架
安装scrapy:
1 | pip install scrapy |
框架:
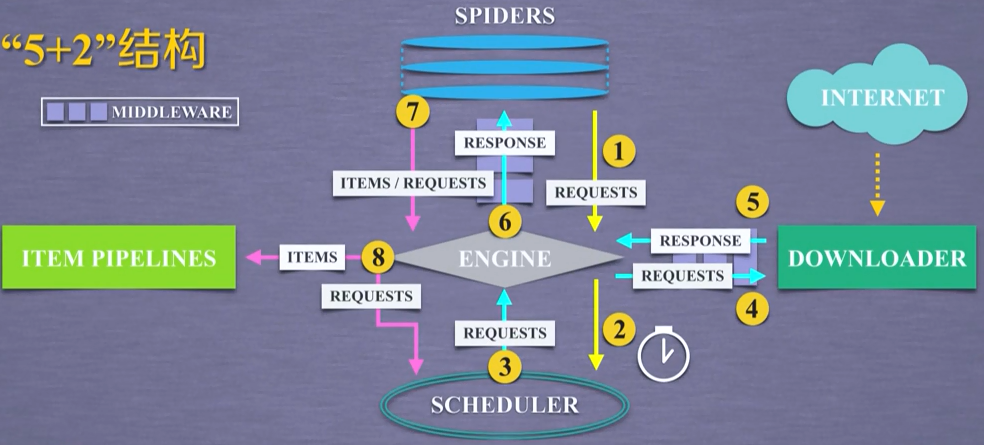
Engine模块(无需修改):
- 控制所有模块之间的数据流
- 根据条件触发事件
Download模块(无需修改):
- 根据用户请求下载网页
Scheduler模块(无需修改):
- 对所有爬取请求进行调度管理
Downloader Middleware中间件(一般无需修改):
- 实施 Engine、 Scheduler和 Downloader之间进行用户可配置的控制
- 用户可以通过该中间件的编写来修改、丢弃、新增请求或响应
Spider模块:
- 解析 Downloader返回的响应( Response)
- 产生爬取项( scraped item)
- 产生额外的爬取请求( Request)
Item Pipelines模块:
- 以流水线方式处理 Spider产生的爬取项.
- 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型.
- 可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库.
Spider Middleware中间件:
- 对请求和肥取项的再处理
- 功能包括修改、丢弃、新增请求或爬取项
和request库的比较
相同点:
- 两者都可以进行页面请求和肥取, Python肥吧虫的两个重要技术路线.
- 两者可用性都好,文档丰富,入门简单.
- 两者都没有处理js、提交表单、应对验证码等功能(可扩展).
不同点:
| request | Scrapy |
|---|---|
| 页面级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能较高 |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般定制灵活,深度定制困难 |
| 上手十分简单 | 入门稍难 |
常用命令
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrap命令行,其格式为:
1 | >scrapy <command> [options] [args] |
常用命令(command)
| 命令 | 说明 | 格式 |
|---|---|---|
| startproject | 创建一个新工程 | scrapy startproject |
| genspider | 创建一个爬虫 | scrapy genspider [options] |
| settings | 获得爬虫配置信息 | scrapy settings [options] |
| crawl | 运行一个爬虫 | scrapy crawl |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动URL调试命令行 | scrapy shell |
步骤
创建工程
1 | scrapy startproject demo |
会产生如下文件:
- demo/:外层目录
- scrapy.cfg:部署 Scrap爬虫的配置文件(服务器上用,本地无需)
- demo/:Scrap框架的用户自定义 Python代码
- __init__.py:初始化脚本
- items.py:Items代码模板(继承类)
- middlewares.py:Middlewares代码模板(继承类)
- pipelines.py:Pipelines代码模板(继承类)
- settings:Scrap爬虫的配置文件
- spiders/:Spiders代码模板目录(继承类)
- __pycache__/:缓存目录,无需修改
- __init__.py:初始化脚本
产生爬虫
1 | cd |
注意:爬虫名字不能和工程同名
会在demo\demo\spiders\下增加demopython123.py:
1 | # -*- coding: utf-8 -*- |
parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求
配置爬虫
修改demopython123.py:
1 | # -*- coding: utf-8 -*- |
运行爬虫
1 | scrapy crawl demopython123 |
捕获页面最终会在\demo\demo.html处
但是实际上,生成的demopython123.py文件是简化版,完整版的如下:
1 | # -*- coding: utf-8 -*- |
完整版和简化版的区别就在于将简化版中的start_urls变量改为了利用yield生成器的函数start_request
Scrap爬虫的使用步骤
- 步骤1:创建一个工程和 Spider模板
- 步骤2:编写 Spider
- 步骤3:编写 Item Pipeline
- 步骤4:优化配置策略
涉及到的类:
- Request类:向网络上提交请求的内容
- Response类:从网络中爬取内容的封装类
- Item类:由Spider产生的信息而封装的类
Request类
class scrapy.http.Request()
- 表示一个Request对象
- 由 Spider生成,由 Downloader执行.
属性或方法:
| 属性或方法 | 说明 |
|---|---|
| .url | Request对应的请求URL地址 |
| .method | 对应的请求方法,‘GET’、'POST’等 |
| .headers | 字典类型风格的请求头 |
| .body | 请求内容主体,字符串类型 |
| .meta | 用户添加的扩展信息,在 Scrapy内部模块间传递信息使用 |
| .copy() | 复制该请求 |
Response类
class scrapy.http.Response()
- Response对象表示一个HTTP响应
- 由 Downloader生成,由 Spider处理
属性或方法:
| 属性或方法 | 说明 |
|---|---|
| .url | Response对应的请求URL地址 |
| .status | HTTP状态码,默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息,字符串类型 |
| .flags | 一组标记 |
| .request | 产生 Response类型对应的 Request对象 |
| .copy() | 复制该响应 |
Item类
class scrapy.http.Item()
- Item对象表示一个从HTML页面中提取的信息内容
- 由 Spider生成,由 Item Pipeline处理
- Item类似字典类型,可以按照字典类型操作
Scrapy爬虫支持多种HTML信息提取方法:
- Beautiful Soup
- Ixml
- re
- XPath Selector
- CSS Selector
CSS Selector基本使用
例子
建立工程
1 | scrapy startproject BaiduStocks |
修改spiders\stocks.py文件:
1 | # -*- coding: utf-8 -*- |
编写Pipelines
- 配置pipelines.py文件
- 定义对爬取项(Scraped Item)的处理类
1 | # -*- coding: utf-8 -*- |
将新的类让框架知道,修改settings.py:
1 | # -*- coding: utf-8 -*- |
执行程序:
1 | scrapy crawl stocks |
优化:
settings.py文件提供如下配置:
| 选项 | 说明 |
|---|---|
| CONCURRENT_REQUESTS | Downloader最大并发请求下载数量,默认32 |
| CONCURRENT_ITEMS | Item Pipeline最大井发ITEM处理数量,默认100 |
| CONCURRENT_REQUESTS_PER_DOMAIN | 每个目标域名最大的并发请求数量,默认8 |
| CONCURRENT_ REQUESTS_PER_IP | 每个目标IP最大的并发请求数量,默认0,非0有效 |