
Go语言
GO语言
该笔记是本人学习《Go语言入门经典》和所记录的,便于以后查阅
零、前言
go中的编码统一为utf-8,其中ascii的字符占一字节,汉字占三字节
GO语言中导入的包或声明的变量 若没有使用则会报错
1 | //格式化源码 |
格式:
1 | //正确: |
标识符相关:
- 下划线“_”本身在Go中是一个特殊的标识符,称为空标识符。可以代表任何其它的标识符,但是它对应的值会被忽略(比如:忽略某个返回值)。所以仅能被作为占位符使用,不能作为标识符使用
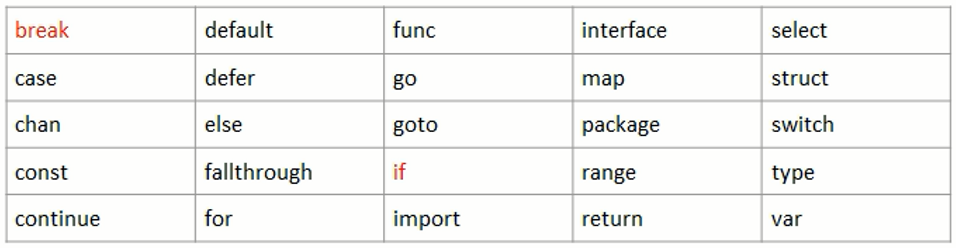
- 保留关键字(注意int、float32等均没有在这里边,不能使用这些作为命名):
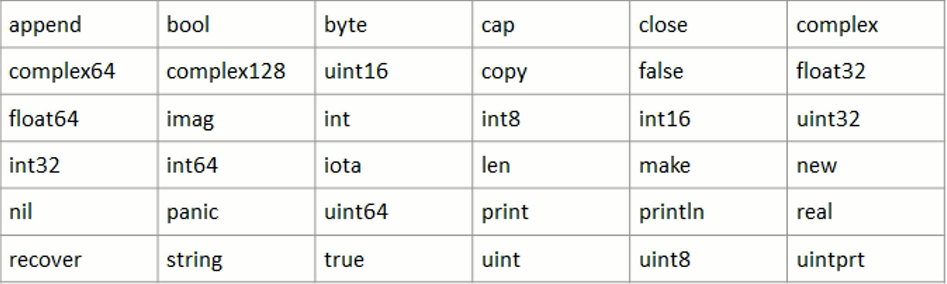
- 预定义标识符:
- 尽量保持:包名和该文件所在目录的名字保持一致
- 首字母大写共有的,首字母小写是私有的(没有public、private等关键字)
运算符相关:
- %运算的本质:$ a%b=a-a/b*b $
- 自增自减只能独立使用,不能和别的语句组合使用,有且仅有
i++和i-- - 没有三目运算符
- 逻辑运算符:
&&、||、! - 位运算符:
&、|、^ - 优先级:
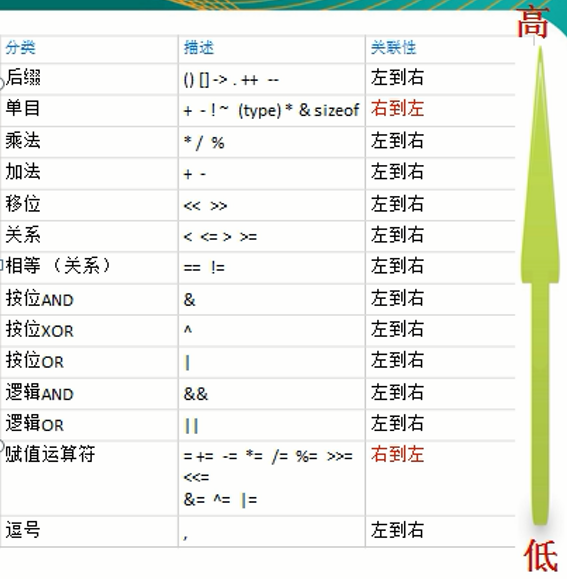
- 只有单目运算符、赋值运算符是从右往左运算
Printf相关:
| 格式化字符串 | 类型 |
|---|---|
| %d | 整形 |
| %f | 浮点型 |
| %T | 输出对应类型 |
| %v | 自动匹配输出 |
| %c | 输出字符型(按asc码输出) |
| %s | 字符串 |
| %t | 布尔类型 |
一、类型(1-4基本 5-end派生)
- 值类型:基本数据类型,int、float、bool、数组、结构体struct
- 变量直接存储,通常在栈中分配
- 引用类型:指针、slice切片、map、管道chan、interface
- 变量存储的是一个地址,这个地址对应的空间才是真正的存储数据(值),内存通常在堆上分配
- 当没有任何变量应引用这个地址时,改地址对应的数据空间就成为一个垃圾,由GC来回收
1.布尔
- true
- false(默认值)
- 占用一个字节
注:Go不能用 1 和 0 代表 true 和 false,未赋值变量默认为false
定义:
1 | var b bool |
2.整数
- 默认值为0
声明:
1 | var i int = 3 |
3.浮点数
- float32:32位
- float64:64位
- 默认值为0(float64)
1 | num1 := .123 |
4.字符串
- 默认值为""
1 | var s string =""//双引号 |
- 不能对字符串执行数学运算
- 字符串是不可变的(不能修改)
- 可以通过‘+’拼接字符串,过长时能够换行(必须以‘+’号结尾)
- println直接输出byte时输出的是ASCII码值
4.5基本数据类型的转换
- 不能自动转换,必须显式转换
- 表达式:
T(V),表示将值V转化为类型T - 基本数据类型转成string
- fmt.Sprintf
- strconv包函数
- func FormatBool(b bool) string
- func Itoa(i int) string
- func FormatInt(i int64, base int) string
- func FormatUint(i uint64, base int) string
- func FormatFloat(f float64, fmt byte, prec, bitSize int) string
- string转成基本数据类型
- strconv包函数
- func ParseBool(str string)(value bool, err error)
- func ParseFloat(s string. bitSize int)(f float64, err error)
- func ParseInt(s string, base int, bitSize int)(i int64, err error)
- func ParseUint(s string, b int, bitSize int)(n uint64, err error)
- 失败时,转换的结果为对应类型的默认值
- strconv包函数
5.数组
- 声明后元素固定,不能增加删除
- 值类型
- 数组的地址为
&数组名
1 | //var 数组名 [数组大小]数组类型 |
遍历:
-
常规遍历
-
for-range结构遍历
基本语法:
1
2
3for index,value := range array01 {
...
}- index:数组下标
- value:该下标对应的值
- 他们都是仅在for循环内部可见的局部变量
- 遍历数组元素的时候,如果不想使用下标 index,可以直接把下标 index标为下划线 _
- index,value不是固定的
注意事项:
- 数组是多个相同类型数据的组合,一个数组一旦声明/定义了,其长度是固定的,不能动态变化
- var arr []int这时arr就是一个slice切片
- 数组中的元素可以是任何数据类型,包括值类型和引用类型,但是不能混用
- 数组创建后,如果没有赋值,有默认值
- 数值类型数组:默认值为0
- 字符串数组:默认值为""
- bool数组:默认值为 false
- 使用数组的步骤
- 1.声明数组并开辟空间
- 2给数组各个元素赋值
- 3使用数组
- 数组的下标是从0开始的
- 数组下标必须在指定范围内使用,否则报 panic:数组越界
- Go的数组属值类型,在默认情况下是值传递,因此会进行值拷贝。数组间不会相互影响
- 如想在其它函数中,去修改原来的数组,可以使用引用传递(指针方式)
- 长度是数组类型的一部分,在传递函数参数时需要考虑数组的长度
5.1切片slice
基本语法:
1 | var 切片名 [] 类型 |
-
切片是数组的一个引用,因此切片是引用类型,在进行传递时,遵守引用传递机制。
-
通过slice改变值后原始数据也会改变
-
slice作为形参时,在函数内部改变slice中的值也会改变元素数据中的值
1
2
3
4
5
6
7
8
9func test(slice []int) {
slice[0] = 100 //这里修改slice[0],会改变实参
}
func main() {
var slice = []int {1, 2, 3, 4}
fmt.Println("slice=", slice) // [1,2,3,4]
test(slice)
fmt.Println("slice=", slice) // [100, 2, 3, 4]
}
-
-
切片的使用和数组类似,遍历切片、访问切片的元素和求切片长度len(slice)都一样
-
切片的长度是可以变化的,因此切片是一个可以动态变化的数组
例子:
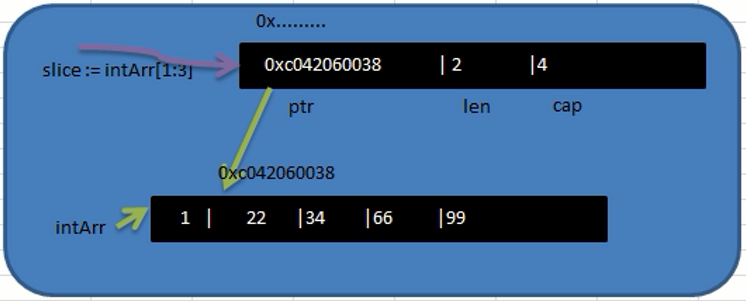
1 | var intArr [5]int = [...]int{1, 22, 33, 66, 99} |
slice从底层来说,其实就是一个数据结构(struct结构体):
1 | //上述例子中的slice的结构可以视为: |
所以可以通过slice来更改原始数据。
上述例子的具体内存模型:
切片的使用:
-
定义一个切片,然后让切片去引用一个已经创建好的数组,如上述例子
- 初始化:var slice = arr[startIndex:endIndex]
- 从arr中的startIndex取到endIndex(不包含endIndex):[startIndex,endIndex)
- 切片初始化时,仍然不能越界。范围在[0-len(arr)]之间,但是可以动态增长
- var slice = arr[0:end] ==> var slice = arr[:end]
- var slice = arr[start:len(arr)] ==> var slice = arr[start:]
- var slice = arr[0:len(arr)] ==> var slice = arr[:]
- 初始化:var slice = arr[startIndex:endIndex]
-
通过内置函数make创建切片
- 语法:
var 切片名 []type = make([],len,[cap])- type:数据类型
- len:大小
- cap:指定切片容量,可选
- 如果没有给切片的各个元素赋值,那么就会使用默认值
- 通过make方式创建的切片对应的数组是由make底层维护,对外不可见,即只能通过slice去访问各个元素
- 语法:
-
定义一个切片,直接就指定具体数组,使用原理类似make的方式
1
2
3
4var strSlice []string = []string{"tom", "jack", "mary"}
fmt.Println("strSlice=", strSlice)
fmt.Println("strSlice size=", len(strSlice)) //3
fmt.Println("strSlice cap=", cap(strSlice)) // ?
上述方式1和2的区别:
- 方式1是直接引用数组,这个数组是事先存在的,程序员是可见的
- 方式2是通过mak来创建切片,make会创建一个数组,是由切片在底层进行维护,程序员是看不见的。
切片的遍历:
- for循环常规遍历
- for-range结构遍历
注意事项:
-
cap是一个内置函数,用于统计切片的容量,即最大可以存放多少个元素 -
切片定义完后,还不能使用,因为本身是一个空的,需要让其引用到一个数组或者make一个空间供切片来使用
-
切片可以继续切片(此时可以不用考虑切片底层的数据结构,即是在切完之后的切片上继续再切,但是所有的这些都是操作的同一片内存空间)
-
使用内置不定参函数
append,可以对切片进行动态追加,append会调整切片的长度1
2
3
4
5
6
7var slice3 []int = []int{100, 200, 300}
//通过append直接给slice3追加具体的元素
slice3 = append(slice3, 400, 500, 600)
fmt.Println("slice3", slice3) //100, 200, 300,400, 500, 600
//通过append将切片slice3追加给slice3
slice3 = append(slice3, slice3...) // 100, 200, 300,400, 500, 600 100, 200, 300,400, 500, 600
fmt.Println("slice3", slice3)- 切片 append操作的本质就是对数组扩容
- go底层会创建一下新的数组 newArr(安装扩容后大小)
- 将slice原来包含的元素拷贝到新的数组 newArr
- slice重新引用到 newArr
- 注意 newArr是在底层来维护的,程序员不可见
-
使用内置函数
copy复制切片中的元素,复制前需声明一个和目标切片类型一致的切片(切片长度没要求,按照小的算)-
copy(para1,para2):para1和para2均为切片类型,从para2拷贝至para1
1
2
3
4
5var slice4 []int = []int{1, 2, 3, 4, 5}
var slice5 = make([]int, 10)
copy(slice5, slice4)
fmt.Println("slice4=", slice4)// 1, 2, 3, 4, 5
fmt.Println("slice5=", slice5) // 1, 2, 3, 4, 5, 0 , 0 ,0,0,0 -
copy会创建一个新的副本
-
-
使用内置不定参函数
append删除元素,append会调整切片的长度,元素的排列顺序不会发生变化- 注意append删除最后的
...
- 注意append删除最后的
1 | //make(数据类型,长度) |
5.2string和slice
-
string底层是一个byte数组,因此 string也可以进行切片处理
-
string和切片在内存的形式,以"abcd"画出内存示意图
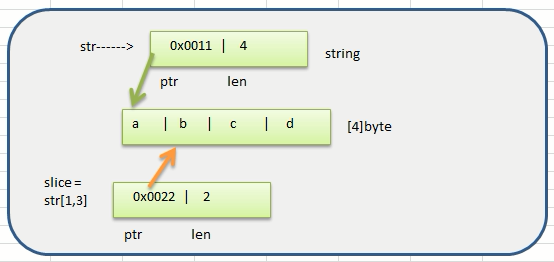
-
string是不可变的,也就说不能通过str[0]=‘z’方式来修改字符串
-
如果需要修改出字符串,可以先将 string -> []byte或者[]rune->修改->重写转成string.
1
2
3
4
5
6
7
8
9
10
11
12
13str := "hello@atguigu"
//"hello@atguigu" =>改成 "zello@atguigu"
arr1 := []byte(str)
arr1[0] = 'z'
str = string(arr1)
fmt.Println("str=", str)
// 细节,我们转成[]byte后,可以处理英文和数字,但是不能处理中文
// 原因是 []byte 字节来处理 ,而一个汉字,是3个字节,因此就会出现乱码
// 解决方法是 将 string 转成 []rune 即可, 因为 []rune是按字符处理,兼容汉字
arr1 := []rune(str)
arr1[0] = '北'
str = string(arr1)
fmt.Println("str=", str)
5.3多维数组(二维数组)
使用:
-
先声明在赋值
-
语法:var 数组名 [大小][大小]类型
1
2
3
4
5
6
7
8
9
10
11
12
13/*
0 0 0 0 0 0
0 0 1 0 0 0
0 2 0 3 0 0
0 0 0 0 0 0
*/
//定义/声明二维数组
var arr [4][6]int
//赋初值
arr[1][2] = 1
arr[2][1] = 2
arr[2][3] = 3
fmt.Println(arr)
-
-
直接初始化
-
语法:var 数组名 [大小][大小]类型 = [大小][大小]类型{ {初值},{初值…} }
1
2
3//arr3 [2][3]int = [2][3]int{{1,2,3}, {4,5,6}}
arr3 := [2][3]int{{1,2,3}, {4,5,6}}
fmt.Println("arr3=", arr3)
-
-
其他几种写法(类似一维数组)
- var 数组名 [大小][大小]类型 = [大小][大小]类型{ {初值},{初值…} }
- var 数组名 [大小][大小]类型 = […][大小]类型{ {初值},{初值…} }
- var 数组名 = [大小][大小]类型{ {初值},{初值…} }
- var 数组名 = […][大小]类型{ {初值},{初值…} }
内存布局:
1 | var arr2 [2][3]int //以这个为例来分析arr2在内存的布局!! |
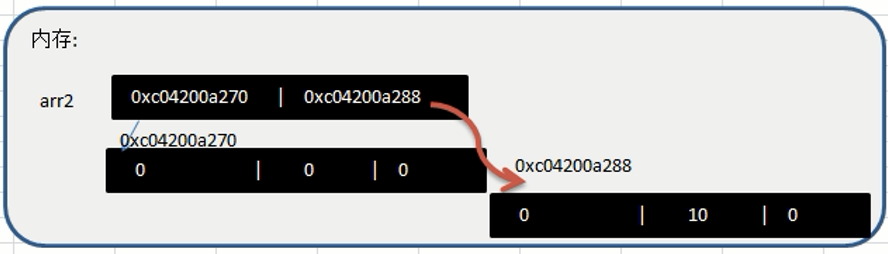
遍历:
-
双层for循环
-
for-range方式遍历
1
2
3
4
5
6
7var arr3 = [2][3]int{{1,2,3}, {4,5,6}}
for i, v := range arr3 {//遍历行
for j, v2 := range v {//遍历行中的元素
fmt.Printf("arr3[%v][%v]=%v \t",i, j, v2)
}
fmt.Println()
}
5.4映射map
map是 key-value数据结构,又称为字段或者关联数组。类似其它编程语言的集合,在编程中是经常使用到。
map是一个无序的结构,不会按照keytype或者valuetype进行排序
可以通过内置函数len获取map的长度
语法:var 变量名 map[keytype]valuetype
- keytype:可以是很多种类型,比如bool,数字, string,指针, channel,还可以是只包含前面几个类型的接口,结构体,数组(keytype通常为int、 string)
- 注意:slice,map还有 function不可以,因为这几个没法用==来判断
- valuetype:类型和keytype基本一致(valuetype通常为数字(整数、浮点)、string、map、struct)
声明:
- var a map[string]string
- var a map[string]int
- var a map[int]string
- var a map[string]map[string]string
- 声明不会分配内存,初始化需要make,分配内存后才能赋值和使用
- make(数据类型,大小)
- a = make(map[string]string, 10)
使用方式:
-
先声明再make
1
2
3var a map[string]string
//在使用map前,需要先make , make的作用就是给map分配数据空间
a = make(map[string]string, 10) -
声明的同时make
1
2
3cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津" -
声明时直接赋值
1
2
3
4
5
6heroes := map[string]string{
"hero1" : "宋江",
"hero2" : "卢俊义",
"hero3" : "吴用",
}
heroes["hero4"] = "林冲"
增删改查:
-
增加和更新
- map[key] = value //如果key还没有,就是增加,如果key存在就是修改
-
删除
- 内置函数
delete:delete(map,"key"), 如果key存在,就删除该 key-value,如果key不存在,不操作,但是也不会报错 - 如果要删除所有元素:
- 遍历后一一delete
- map = make(),make一个新的,让原来的成为垃圾,被gc回收
- 内置函数
-
查找
-
直接找
1
2
3
4
5
6val, ok := cities["no2"]
if ok {
fmt.Printf("有no1 key 值为%v\n", val)
} else {
fmt.Printf("没有no1 key\n")
}
-
遍历(只能for-range):
1 | studentMap := make(map[string]map[string]string) |
注意事项:
- map是引用类型,遵守引用类型传递的机制,在一个函数接收map,修改后,会直接修改原来的map
- map的容量达到后,再想map增加元素,会自动扩容(无需借助其他函数,也不用管make中指定的大小),并不会发生 panic,也就是说map能动态的增长键值对( key-value)
- map的value也经常使用 struct类型,更适合管理复杂的数据(比前面value是一个map更好),比如value为 Student结构体
5.5map切片及排序
map切片:
切片的数据类型如果是map,则我们称为 slice of map,map切片,这样使用则map的个数就可以动态变化(利用append)
1 | //1. 声明一个map切片 |
map排序:
- 先将map的key 放入到 切片中
- 对切片排序
- 遍历切片,然后按照key来输出map的值
例子:
1 | map1 := make(map[int]int, 10) |
6.检测变量类型
- 依赖
reflect包
1 | var s string = "string" |
7.类型转换
字符串和其他类型互换:
- 依赖
strconv包
二、变量
-
使用关键字
var声明 -
声明后不能再次声明,但是可以重新赋值
-
变量声明后若未给与指定值将会设为默认值,不同变量类型默认值不一样,这种默认值称为零值
1.快捷声明
多个同类型变量:
1 | var s,t string = "foo","bar" |
多个不同类型变量:
1 | //全局 |
2.简短声明
- 编译器会自动推断变量类型
- 只能在函数中使用
1 | s := "hello World" |
3.省略变量名声明
1 | var s = "hello World" |
- 一般来说在函数内使用简短声明,在函数外省略变量名声明
4.指针
- &:取地址
- *变量名:指针,eg:*int:int类型指针
- *指针:取指针中的值
- 详见第五章
5.常量
- 可以引用,但是不能修改
- 关键字
const修饰 - 定义时就必须初始化
- 常量只能修饰bool、数字类型(int、float)、string类型
1 | const str string = "hello" |
注意事项:
1 | //简洁的写法: |
- golang中没有常量名必须字母大写的规定
- 仍然通过首字母的大小写来控制常量的访问范围
三、函数和包
1.基本格式
- 关键字
func修饰 - 函数签名:函数的第一行,即
func 函数名(变量类型1 参数1,变量类型2 参数2,...) 返回值类型
1 | func 函数名(参数1 变量类型1,参数2 变量类型2,...) (返回值类型) { |
eg:
多个返回值:
1 | package main |
注意事项:
- 基本数据类型和数组都是值传递,在函数内修改不会影响到原来的值
- 如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量。从效果上看类似引用
- 不支持传统的函数重载
- 函数本身也是一种数据类型,可以作为形参并且调用
- go支持自定义数据类型
- 语法:
type 自定义数据类型名 数据类型
- 语法:
- 支持函数返回值命名
- 使用
_标识符,忽略返回值 - 支持可变参数
- args是slice切片,通过args[index]可以访间到各个值。
- 可变参数需要放在形参列表的最后一个
2.不定参数函数
- 使用
...指定不定参
eg:
1 | package main |
3.具名返回值
- 函数返回前将赋值给具名变量
- 无需显示的返回相应的变量
1 | func sayHi() (x,y string) { |
4.init函数
每一个源文件都可以包含一个init函数,该函数会在main函数执行前,被Go运行框架调用,也就是说init会在main函数前被调用。
注意事项:
- 如果一个文件同时包含全局变量定义,init函数和main函数,则执行的流程是:全局变量定义->init函数->main函数
- init函数最主要的作用,就是完成一些初始化的工作
- 如果main.go和main包含的其他包中都有init函数,首先应优先执行包含包中的变量定义->init函数->main中变量定义->init函数->main函数
5.匿名函数
Go支持匿名函数,如果我们某个函数只是希望使用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用
全局匿名函数:如果将匿名函数赋给一个全局变量,那么这个匿名函数,就成为一个全局匿名函数,可以在程序有效。
使用方式:
-
在定义匿名函数时就直接调用
1
2
3res := func(n1 int,n2 int) int {
return n1 + n2
}(10,20) -
将匿名函数赋给一个变量(函数变量),再通过该变量来调用匿名函数
1
2
3
4a := func(n1 int,n2 int) int {
return n1 + n2
}//a的数据类型就是函数类型
res := a(10,20)
6.内置函数
- len
- new:用来分配内存,主要用来分配值类型,比如int、foat32、struct。返回的是指针
- make:用来分配内存,主要用来分配引用类型,比如chan、map、 slice。
7.包
- 包的本质实际上就是创建不同的文件夹,来存放程序文件。
- 基本概念:go的每一个文件都是属于一个包的,也就是说go是以包的形式来管理文件和项目目录结构的
- 作用:
- 区分相同名字的函数、变量等标识符
- 当程序文件很多时,可以很好的管理项目
- 控制函数、变量等访问范围,即作用域(首字母大写共有,小写私有)
语法:
1 | //打包: |
细节说明:
-
在给一个文件打包时,该包对应一个文件夹,比如这里的utis文件夹对应的包名就是 utils,文件的包名通常和文件所在的文件夹名一致,般为小写字母。
- 不一致的话,调用包中的函数时,包名就得变更为具体的包名
- import导入的在某种意义上相当于导入包所在的路径
-
使用前需要先引用对应的包
-
打包指令应该在第一行然后才能是import指令
-
在import包时,路径从
$GOPATH的src下开始,不用带src,编译器会自动从src下开始引入 -
首字母大写共有,小写私有
-
在访问其它包函数时,其语法是
包名.函数名 -
go支持给包取别名
- 别名后只能通过
别名.函数名访问
1
2
3
4
5
6
7
8import(
"fmt"
util "go_code/chapter06/fundemo01/utils"//取别名为util
)
func main(){
util.Cal()//只能通过别名.函数名调用
} - 别名后只能通过
-
在同一包下(可以是不同文件),不能有相同的函数名和全局变量名,否则报重复定义
-
如果你要编译成一个可执行程序文件,就需要将这个包声明为man,即 package main,这就是一个语法规范。如果你是写一个库,包名可以自定
- main包只有一个
- 编译后生成一个有默认名的可执行文件,在
$GOPATH目录下,可以指定名字和目录,比如:放在bin目录下:D: goproject> gobuild -o bin/my.exe go_code/chapter06/fundemo01/main
7.闭包
闭包就是一个函数和与其相关的引用环境组合的一个整体(实体)
1 | func AddUpper() func (int) int { |
- 返回的是一个匿名函数,但是这个匿名函数引用到函数外的n因此这个匿名函数就和n形成个整体,构成闭包
- 可以这样理解:闭包是类,函数是操作,n是字段。函数和它使用到的n构成闭包
- 当我们反复的调用f函数时,因为n只初始化一次,因此每调一次就进行累计
- 闭包中的变量只会初始化一次且会一直保存
- 我们要搞清楚闭包的关键,就是要分析出返回的函数它使用(引用)到哪些变量,因为函数和它引用到的变量共同构成闭包。
四、控制流程
1.if
- 支持在if条件中直接定义一个变量
- 大括号不能省
- 条件可以用小括号,但是不推荐
1 | if 套件表达式 { |
1.1运算符
1.1.1比较
- 双方需要类型一致
| 字符 | 运算符 |
|---|---|
| == | |
| != | |
| < | |
| <= | |
| > | |
| >= |
1.1.2算术
- 双方需要类型一致
| 字符 | 运算符 |
|---|---|
| + | |
| - | |
| * | |
| / | |
| % | 余(模) |
1.1.3逻辑
| 字符 | 运算符 |
|---|---|
| && | 与 |
| || | 或 |
| ! | 非 |
2.switch
1 | switch 变量值 { |
fallthrough:switch穿透,如果在case语句块后增加fallthrough,则会继续执行下一个case- Type Switch: switch语句还可以被用于 type-switch来判断某个 interface变量中实际指向的变量类型
3.for
语法格式:
1 | for 循环变量初始化;循环条件;循环变量迭代 { |
- 可以配合break退出循环
- beak语句出现在多层嵌套的语句块中时,可以通过标签指明要终止的是哪层语句块
- 可以配合continue退出本次循环
- continue语句出现在多层嵌套的语句块中时,可以通过标签指明要跳过的是哪层语句块
- 可以通过goto语句可以无条件地转移到程序中指定的行
- 在Go程序设计中般不主张使用goto语句,以免造成程序流程的混乱,使理解和调试程序都产生困难
1 | for i < 10 { |
初始化语句:
1 | for i := 0;i < 10; i++ { |
遍历数组:
1 | for i,n := range numbers { |
遍历字符串:
1 | for i := 0,n := len(str);i++ {//按照字节处理,如有中文会乱码 |
4.defer
在函数中,程序员经常需要创建资源比如:数据库连接、文件句柄、锁等),为了在函数执行完后及时的释放资源,Go的设计者提供 defer(延时机制)
- 用于执行清理操作或者确保操作完成后再执行另一个函数
- 即,在defer所在的函数执行完毕后执行另一个函数
- 多条defer语句的输出将按照与defer出现的顺序相反的顺序执行
例子:
1 | func sum(n1 int, n2 int) int { |
注意:
- 当go执行到一个 defer时,不会立即执行 defer后的语句,而是将defer后的语句压入到一个栈中[暂时称该栈为 defer栈]然后继续执行函数下一个语句
- 当函数执行完毕后,在从 defer栈中,依次从栈顶取出语句执行(注:遵守栈先入后出的机制)。
- 在 defer将语句放入到栈时,也会将相关的值拷贝同时入栈。
五、结构体和指针
1.结构体
面向对象编程说明:
- Galang也支持面向对象编程(OOP),但是和传统的面向对象编程有区别,并不是纯粹的面向对象语言。所以我们说 Galang支持面向对象编程特性是比较准确的。
- Galang没有类(class),Go语言的结构体( struct)和其它编程语言的类(class)有同等的地位,你可以理解 Galang是基于 struct来实现OOP特性的
- Galang面向对象编程非常简洁,去掉了传统OOP语言的继承、方法重载、构造函数和析构函数、隐藏的this指针等等
- Galang仍然有面向对象编程的继承,封装和多态的特性,只是实现的方式和其它OOP语言不一样,比如继承: Galang没有 extends关键字,继承是通过匿名字段来实现
- Galang面向对象(OOP)很优雅,OOP本身就是语言类型系统( type system)的一部分,通过接口 (interface)关联,耦合性低,也非常灵活。也就是说在 Galang中面向接口编程是非常重要的特性
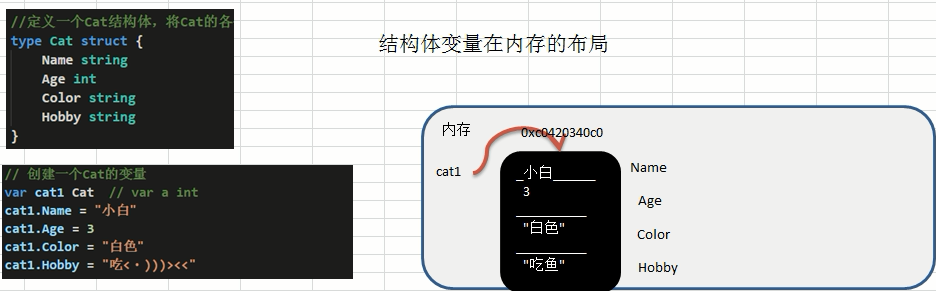
结构体是值类型,其在内存中的布局如下所示:
1.1声明
1 | type 结构体名称 struct{ |
- 字段/属性:结构体字段=属性= field,字段是结构体的一个组成部分,一般是基本数据类型、数组,也可是引用类型。
- 字段声明同变量
- 在创建一个结构体变量后,如果没有给字段赋值,都对应一个零值(默认值),规则同前面讲的一样
- 同结构体变量的字段是独立,互不影响,一个结构体变量字段的更改,不影响另外一个。
- 关键字
type指定一种新类型 - 关键字
struct指定为结构体 - 可以使用关键字
new创建结构体实例 - 使用
.访问结构体中的成员 - 声明或创建后不能再修改其成员的数据类型
- 每个字段独占一行时,最后一个字段结尾必须加逗号
- 结构体可以嵌套
1 | //声明 |
- 结构体指针访问字段的标准方式应该是:
(*结构体指针).字段名 - go做了一个简化,也支持
结构体指针.字段名,更加符合程序员使用的习惯,go编译器底层对结构体指针.字段名做了转化(*结构体指针).字段名 (*结构体指针).字段名不能写成*结构体指针.字段名:.的优先级高于*
1.2自定义结构体字段的默认值
- 可以利用自定义函数(构造函数)专门来给自定义的结构体赋自定义的默认值
| 类型 | 零值(默认值) |
|---|---|
| 布尔型 | flase |
| 整形 | 0 |
| 浮点型 | 0.0 |
| 字符串 | “” |
| 指针 | nil |
| 函数 | nil |
| 接口 | nil |
| 切片slice | nil |
| 通道 | nil |
| 映射map | nil |
1.3结构体比较
- 只能比较字段均一致的结构体
- 可以使用
reflect包检查结构体类型
- 可以使用
- 只有==和!=
- 结构体或字段的首字母大写才能导出(公有值)
1.4结构体注意事项
-
结构体的所有字段在内存中是连续的
-
结构体是用户单独定义的类型,和其它类型进行转换时(利用强制类型转化)需要有完全相同的字段(名字、个数和类型)
-
结构体进行type重新定义(相当于取别名), Golang认为是新的数据类型,但是相互间可以强制类型转化
-
struct的每个字段上,可以写上一个tag,该tag可以通过反射机制获取,常见的使用场景就是序列化和反序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34package main
import "fmt"
import "encoding/json"
type A struct {
Num int
}
type B struct {
Num int
}
type Monster struct{
Name string `json:"name"` // `json:"name"` 就是 struct tag
Age int `json:"age"`
Skill string `json:"skill"`
}
func main() {
var a A
var b B
a = A(b) // ? 可以转换,但是有要求,就是结构体的的字段要完全一样(包括:名字、个数和类型!)
fmt.Println(a, b)
//1. 创建一个Monster变量
monster := Monster{"牛魔王", 500, "芭蕉扇~"}
//2. 将monster变量序列化为 json格式字串
// json.Marshal 函数中使用反射,这个讲解反射时,会详细介绍
jsonStr, err := json.Marshal(monster)//若将Monster中的字段改成小写,就不能够调用(作用域限制),这里只能够用tag
if err != nil {
fmt.Println("json 处理错误 ", err)
}
fmt.Println("jsonStr", string(jsonStr))
}
2.指针
1 | type Movie struct{ |
六、方法和接口
1.方法
- Galang中的方法是作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是 struct
- 与函数类似,有关键字
func指定,会在func后添加另一个参数表 - 可以建立多个方法,构成方法集
- 方法和某个结构体紧密绑定,可以通过
结构体.方法名的形式调用属于该结构体的方法 - 方法中的接受者类型类似一般用指针,以便直接修改结构体内部成员。如果不使用指针,修改后的值将不会保存,相当于拷贝了一份原结构体的副本来进行操作
1 | func (接受者参数 接受者类型) 方法名(参数列表) (返回值列表) { |
- 接受者类型type:表示这个方法和type这个类型进行绑定,或者说该方法作用于type类型
- type可以是结构体,也可以其它的自定义类型
- 接受者参数:就是type的一个实例(变量)
eg:
1 | package main |
- 方法的调用和传参机制和函数基本一样,不一样的地方是方法调用时会将调用方法的变量,当做实参也传递给方法。
结构体创建及赋值:
1 | //方式1 |
注意事项:
- 结构体类型是值类型,在方法调用中,遵守值类型的传递机制,是值拷贝传递方式
- 如程序员希望在方法中,修改结构体变量的值,可以通过结构体指针的方式来处理
- Golang中的方法作用在指定的数据类型上的(即:和指定的数据类型绑定)因此自定义类型,都可以有方法,而不仅仅是 struct,比如int,foat32等都可以有方法
- 方法的访问范围控制的规则,和函数一样。方法名首字母小写,只能在本包访问,方法首字母大写,可以在本包和其它包访问。
- 如果一个变量实现了**String()**这个方法,那么 fmt.Println默认会调用这个变量的String()进行输出(这里的类型必须一样,若绑定的方法接受者类型为指针,则输入参数一定要加&)
方法和函数的区别:
-
调用方式不一样
- 函数:函数名(实参列表)
- 方法:变量.方法名(实参列表)
-
对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然
-
对于方法(如 struct的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以。最终的决定权在方法的接受者类型上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24type Person struct {
Name string
}
//对于方法(如struct的方法),
//接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以
func (p Person) test03() {
p.Name = "jack"
fmt.Println("test03() =", p.Name) // jack
}
func (p *Person) test04() {
p.Name = "mary"
fmt.Println("test03() =", p.Name) // mary
}
func main() {
p := Person{"tom"}
p.test03()
fmt.Println("main() p.name=", p.Name) // tom
(&p).test03() // 从形式上是传入地址,但是本质仍然是值拷贝
fmt.Println("main() p.name=", p.Name) // tom
(&p).test04()
fmt.Println("main() p.name=", p.Name) // mary
p.test04() // 等价 (&p).test04 , 从形式上是传入值类型,但是本质仍然是地址拷贝
}
2.接口(详见十一章)
- 使用关键字
interface指定接口 - 可以理解为方法集的一个蓝本(充当了方法集的规范),描述了方法集中的所有方法,但并没有实现它
- 描述了方法集中的所有方法,并指定了每个方法的函数签名
- 使用接口前需要实现接口,即满足接口要求:
- 实现接口指定方法集
- 函数签名正确无误
- 接口是一种类型,可以作为参数传递给函数
1 | type 接口名称 interface { |
七、字符串
- 字符串实际上是只读的字节切片
1.字面量
- 与C语言类型,利用双引号括起来
- 可以使用基于反斜杠的各种转义字符
2.rune字面量
- 使用反引号
·括起来(Esc键下的那个) - 不能使用转义字符,是什么格式写在代码里就怎么输出
3.拼接字符串
- 使用运算符
+或+=拼接 - 只能拼接字符串型变量
- 可以使用strconv包中的Itoa方法将整数转化为字符串
- 拼接次数增多会导致效率边低
- 可使用缓存区解决
4.strings包处理字符串
- strings.ToLower:将字符串转化为小写
- strings.Index:在字符串中查找子串并返回索引
- strings.TrimSpace:去除开头和结尾的空格
5.常用系统函数
- 统计字符串长度,按照字节:len(str),内嵌函数,无需包
- 字符串遍历,同时处理有中文的间题 r := []rune(str)
- 字符串 转 整数:n,err := strconv.Atoi(“12”)
- 整数 转 字符串str = strconv.Itoa(12345)
- 字符串 转 []byte: var bytes = []byte(“hello go”)
- []byte 转 字符串:str = string([]byte{97,98,99})
- 10进制 转 2,8,16进制:str = strconv.FormatInt(123,2)
- 查找子串是否在指定的字符串中: strings.Contains(“seafood”,“foo”)//true
- 统计一个字符串有几个指定的子串: strings.Count(“cheese”,“e”)//4
- 不区大小写的字符串比较(==比较是区分字母大小写的): fmt.PrintIn( strings.EqualFold(“abc”,“Abc”)//true
- 返回子串在字符串第一次出现的index值,如果没有返回-1: strings.Index(“NTL_abc”,“abc”)//4
- 返回子串在字符串最后一次出现的index,如没有返回-1: strings.Lastlndex(“go golang”,“go”)//3
- 将指定的子串替换成另外一个子串: strings.Replace(“go go hello”,“go”,“go语言”,n)n可以指定你希望替换几个,如果n=-1表示全部替换
- 按照指定的某个字符,为分割标识,将一个字符串拆分成字符串数组:strings.Split(“hello,wrold,ok”,“,”)
- 将字符串的字母进行大小写的转换: strings.ToLower(“Go”)//go strings.ToUpper(“Go”)//Go
- 将字符串左右两边的空格去掉: strings.TrimSpacel(" tn a lone gopher ntrn ")
- 将字符串左右两边指定的字符去掉: strings.Trim(“! hello!”," !“)//[“hello”]//将左右两边!和” "去掉
- 将字符串左边指定的字符去掉: strings.TrimLeft(“! hello!”," !“)//[“hello”]//将左边!和” "去掉
- 将字符串右边指定的字符去掉: strings.TrimRight(“! hello!”," !“)//[“hello”]//将右边!和” "去掉
- 判断字符串是否以指定的字符串开头: strings.HasPrefix(“ftp://192.168.10.1",“ftp”)//true
- 判断字符串是否以指定的字符串结束: strings.HasSuffix(“NLT_abc. jpg”,“abc”)//false
八、处理错误
1.错误的处理机制
基本说明:
- Go语言追求简洁优雅,所以,Go语言不支持传统的try…catch…finally这种处理
- Go中引入的处理方式为:
defer,panic,recover - 这几个异常的使用场景可以这么简单描述:Go中可以抛出一个 panic的异常,然后在 defer中通过 recover捕获这个异常,然后正常处理
例子:
1 | //该函数调用后不会终止(会运行匿名函数),任然会正常运行 |
2.自定义错误
-
没有错误,返回的错误值为nil
-
一般错误是通过返回给他的调用者处理的
-
错误是一个值,在标准库中声明了接口error
1
2
3type error interface {
Error() string
}
1.1创建错误
-
使用标准库中的
errors包1
2
3
4
5err := errors.New("错误内容")
if err != nil{
fmt.Println(err)
panic(err)
} -
使用标准库中的
fmt包中的Errorf方法灵活的创建1
2
3
4
5
6role,name := "Richard Jupp","Drummer"
err := fmt.Errorf("The %v %v quit",role,name)
if err != nil{
fmt.Println(err)
panic(err)
}
1.2 panic内置函数
- 慎用
- 内置函数,接收一个interface{}类型的值(也就是任何值了)作为参数。可以接收error类型的变量,输出错误信息,并退出程序
- 是go语言中的内置函数,能够终止正常的控制流程并引起恐慌,导致程序停止执行
九、Goroutine协程
- 关键字
go修饰 - 是一种支持并发编程的方式
- 用于处理需要并发的任务
- 占用内存极小,且创建和销毁效率也很高
进程和线程:
- 进程就是程序程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
- 线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位。
- 一个进程可以创建核销毁多个线程,同一个进程中的多个线程可以并发执行
- 一个程序至少有一个进程,一个进程至少有一个线程
并发和并行:
- 多线程程序在单核上运行,就是并发
- 多线程程序在多核上运行,就是并行
go协程和go主线程
- Go主线程(有程序员直接称为线程/也可以理解成进程一个Go线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程
- Go协程的特点
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程
例子:
2
3
4
5
6
7
8
go test() // 开启了一个协程
for i := 1; i <= 10; i++ {
fmt.Println(" main() hello,golang" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
- 如果主线程退出了,则协程即使还没有执行完毕,也会退出
- 当然协程也可以在主线程没有退出前,就自己结束了,比如完成了自己的任务
协程的调度模型(MPG模式):
- M:操作系统的主线程(是物理线程)
- P:协程执行需要的上下文
- G:协程
设置Golang运行的cpu数:
1 | import "runtime" |
- go1.8后,默认让程序运行在多个核上可以不用设置了
- go1.8前,还是要设置一下,可以更高效的利益cpu
1.多个协程之间的通信
在编译程序时,可以通过增加-race参数,即可查看是否存在资源竞争,如:
1 | > go build -race test.go |
sync包提供了一些基本的同步元素,如互斥锁。大部分都是适用于低水平程序线程,高水平的同步使用channel通信更好一些。
例子:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import (
"fmt"
_ "time"
"sync"
)
// 需求:现在要计算 1-200 的各个数的阶乘,并且把各个数的阶乘放入到map中。
// 最后显示出来。要求使用goroutine完成
var (
myMap = make(map[int]int, 10)
//声明一个全局的互斥锁lock
lock sync.Mutex
)
// test 函数就是计算 n!, 让将这个结果放入到 myMap
func test(n int) {
res := 1
for i := 1; i <= n; i++ {
res *= i
}
//这里我们将 res 放入到myMap
lock.Lock()//加锁
myMap[n] = res //concurrent map writes?
lock.Unlock()//解锁
}
func main() {
// 我们这里开启多个协程完成这个任务[200个]
for i := 1; i <= 20; i++ {
go test(i)
}
//休眠10秒钟【第二个问题 】
//time.Sleep(time.Second * 5)
lock.Lock()//这里加锁是为了让go底层知道(go底层可能仍会访问改资源)
for i, v := range myMap {
fmt.Printf("map[%d]=%d\n", i, v)
}
lock.Unlock()
}
更好的通信机制应该是用到下一章的管道
十、channel通道
- 一种与Goroutine通信的方式
- 能够让数据进入和离开Goroutine,方便Goroutine之间进行通信
- 使用关键字
make创建,使用关键字chan指定创建的是通道 - channel的本质就是一个数据结构——队列
- 先进先出
- 线程安全,多 goroutine访问时,不需要加锁,就是说 channel本身就是线程安全
- channel是有类型的,一个 string的channel只能存放 string类型数据
声明:
1 | var 变量名 chan 数据类型 |
- channel是引用类型
- channel必须初始化才能写入数据(即make后)
- 管道是有类型的
初始化:
1 | 管道变量名字 = make(chan 通道存储的数据类型,管道中的容量) |
数据传输:
向通道发送消息(注意通道只能接受创建时指定的通道类型):
1 | var intChan chan int |
len(intChan):获取到通道的长度,具体为传入通道中的数据cap(intChan):获取通道的容量,具体为make创建时的大小- 给管写入数据时,不能超过其容量
从通道接收消息:
1 | var num2 int |
- 在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报deadlock
注意:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Name string
Age int
}
func main() {
//定义一个存放任意数据类型的管道 3个数据
//var allChan chan interface{}
allChan := make(chan interface{}, 3)
allChan<- 10
allChan<- "tom jack"
cat := Cat{"小花猫", 4}
allChan<- cat
//我们希望获得到管道中的第三个元素,则先将前2个推出
<-allChan
<-allChan
newCat := <-allChan //此时从管道中取出的Cat是一个空接口
fmt.Printf("newCat=%T , newCat=%v\n", newCat, newCat)//newCat=main.Cat , newCat=<小花苗 4> 此处能够打印出来是在运行的层面上
//下面的写法是错误的!编译不通过
//fmt.Printf("newCat.Name=%v", newCat.Name)//此处不能编译通过是在编译的层面上发现类型不匹配(接口中不能有字段)
//使用类型断言 强制转换
a := newCat.(Cat)
fmt.Printf("newCat.Name=%v", a.Name)
}
管道关闭:
使用内置函数close可以关闭 channel,当 channel关闭后,就不能再向 channel写数据,但是仍然可以从该 channel读取数据。
1 | intChan := make(chan int, 3) |
管道关闭后,数据全部读取完毕后假设再次读取,此时会返回一个错误值:
1 | n1,ok := <-intChan//ok用于保存错误值 |
但是假设没有关闭就再次读,会发生deadlock,与下面的for- range遍历类似
- 未关闭管道一直读会发生
deadlock,但是关闭后读就只会返回正确与否,不会产生deadlock。可以理解为留下一个标志位,读到这个标志位就停止 - 在没有关闭管道前也可以读取管道中的内容
管道遍历:
channel支持for- range的方式进行遍历,请注意两个细节
- 1)在遍历时,如果 channel没有关闭,则会出现
deadlock的错误- 因为所有数据全部取出后,仍会再次取数据,此时会产生
deadlock的错误 - 如果写的快,读得慢,写满后写入方会阻塞,但是只要有读取就不会发生
deadlock。反之,编译器底层发现一直在写而没有读取就会发生deadlock - 总之,只要管道有流动就不会发生
deadlock
- 因为所有数据全部取出后,仍会再次取数据,此时会产生
- 2)在遍历时,如果 channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
1 | intChan2 := make(chan int, 100) |
Goroutine协程+channel管道
协程+管道例子:
同时读写协作问题
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
func writeData(intChan chan int) {
for i := 1; i <= 50; i++ {
//放入数据
intChan<- i //
fmt.Println("writeData ", i)
//time.Sleep(time.Second)
}
close(intChan) //关闭
}
//read data
func readData(intChan chan int, exitChan chan bool) {
for {
v, ok := <-intChan
if !ok {
break
}
time.Sleep(time.Second)
fmt.Printf("readData 读到数据=%v\n", v)
}
//readData 读取完数据后,即任务完成
exitChan<- true
close(exitChan)
}
func main() {
//创建两个管道
intChan := make(chan int, 10)
exitChan := make(chan bool, 1)
go writeData(intChan)
go readData(intChan, exitChan)
//time.Sleep(time.Second * 10)
for {
_, ok := <-exitChan
if !ok {
break
}
}
}阻塞问题
上述例子,如果只有写入数据而没有读取,就会出现阻塞而deadlock,原因是 intChan容量是10,而代码 writeData会写入50个数据阻塞在 writeData的ch<-i
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//创建两个管道
intChan := make(chan int, 10)
exitChan := make(chan bool, 1)
go writeData(intChan)
//go readData(intChan, exitChan)
//等待readData协程完成
for {
_, ok := <-exitChan
if !ok {
break
}
}
}
写管道和读管道的频率不一致,无所谓
注意细节:
-
channel可以声明为只读或只写(默认为双向,可读可写)
1
2
3
4
5
6
7
8
9
10
11
12//声明为只写
var chan2 chan<- int//chan<-可以理解为属性,稍微修饰下,并不能通过make(chan<- int)创建,下面同理
chan2 = make(chan int, 3)
chan2<- 20
//num := <-chan2 //error
fmt.Println("chan2=", chan2)
//声明为只读
var chan3 <-chan int
num2 := <-chan3
//chan3<- 30 //err
fmt.Println("num2", num2) -
使用select可以解决从管道取数据的阻塞问题
-
传统方法在遍历时,如果不关闭会因为阻塞而导致deadlock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan<- i
}
//定义一个管道 5个数据string
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
//在实际开发中,可能我们不好确定什么关闭该管道.
//可以使用select 方式可以解决
for {
select {
//注意: 这里,如果intChan一直没有关闭,不会一直阻塞而deadlock
//会自动到下一个case匹配
case v := <-intChan :
fmt.Printf("从intChan读取的数据%d\n", v)
time.Sleep(time.Second)
case v := <-stringChan :
fmt.Printf("从stringChan读取的数据%s\n", v)
time.Sleep(time.Second)
default :
fmt.Printf("都取不到了,不玩了, 程序员可以加入逻辑\n")
time.Sleep(time.Second)
return
}
} -
协程中使用recover,可以解决因协程中出现panic而导致整个程序崩溃的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27func sayHello() {
for i := 0; i < 10; i++ {
time.Sleep(time.Second)
fmt.Println("hello,world")
}
}
func test() {
//这里我们可以使用defer + recover
defer func() {
//捕获test抛出的panic
if err := recover(); err != nil {
fmt.Println("test() 发生错误", err)
}
}()
//定义了一个map
var myMap map[int]string
myMap[0] = "golang" //error
}
func main() {
go sayHello()
go test()
for i := 0; i < 10; i++ {
fmt.Println("main() ok=", i)
time.Sleep(time.Second)
}
}
-
十一、面向对象编程
1.构造函数(工厂模式间接实现)
Golang的结构体没有构造函数,通常可以使用工厂模式来解决这个问题
使用工厂模式实现跨包创建结构体实例(变量):
-
如果 modle包的结构体变量首字母大写,引入后,直接使用,没有问题
-
如果mode包的结构体变量首字母小写,引入后,不能直接使用,可以工厂模式解决
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31//main.go
func main() {
//创建要给Student实例
// var stu = model.Student{
// Name :"tom",
// Score : 78.9,
// }
//定student结构体是首字母小写,我们可以通过工厂模式来解决
var stu = model.NewStudent("tom~", 98.8)
fmt.Println(*stu) //&{....}
fmt.Println("name=", stu.Name, " score=", stu.GetScore())
}
//student.go
package model
//定义一个结构体
type student struct{
Name string
score float64
}
//因为student结构体首字母是小写,因此是只能在model使用
//我们通过工厂模式来解决
func NewStudent(n string, s float64) *student {
return &student{
Name : n,
score : s,
}
}
//如果score字段首字母小写,则,在其它包不可以直接方法,我们可以提供一个方法
func (s *student) GetScore() float64{
return s.score //ok
}
2.封装
封装( encapsulation)就是把抽象出的字段和对字段的操作封装在一起,数据被保护在内部,程序的其它包只有通过被授权的操作(方法),才能对字段进行操作
如何体现封装:
- 对结构体中的属性进行封装
- 通过方法,包 实现封装
步骤:
-
将结构体、字段(属性)的首字母小写(不能导出了,其它包不能使用,类似 private)
-
结构体所在包提供一个工厂模式的函数,首字母大写。类似一个构造函数
-
提供一个首字母大写的Set方法(类似其它语言的 public),用于对属性判断并赋值
1
2
3func (var 结构体类型名) SetXxx(参数列表)(返回值列表){
//加入数据验证的业务逻辑
} -
提供一个首字母大写的Get方法(类似其它语言的public,用于获取属性的值
1
2
3func (var 结构体类型名) GetXxx(){
return var.字段
} -
特别说明:在 Golang开发中并没有特别强调封装,Galang本身对面向对象的特性做了简化
3.继承
继承可以解决代码复用,让我们的编程更加靠近人类思维。
当多个结构体存在相同的属性(字段)和方法时,可以从这些结构体中抽象出结构体,在该结构体中定义这些相同的属性和方法
其它的结构体不需要重新定义这些属性和方法,只需嵌套一个匿名结构体即可。
在 Golang中,如果一个 struct嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承特性
1 | type Student struct { |
-
结构体可以使用嵌套匿名结构体所有的字段和方法,即:首字母大写或者小写的字段、方法,都可以使用。
-
匿名结构休字段访问可以简化:
变量名.匿名结构体名.成员–>变量名.成员 -
当结构体和匿名结构体有相同的字段或者方法时,编译器采用就近访问原则访问,如希望访问匿名结构体的字段和方法,可以通过匿名结构体名来区分
-
结枃体嵌入两个(或多个)匿名结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有同名的字段和方法),在访问时,就必须明确指定匿名结构体名字,否则编译报错。
-
如果一个 struct嵌套了一个有名结构体,这种模式就是组合,如果是组合关系,那么在访问组合的结构体的字段或方式时,必须带上结构体的名字
-
嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26type Goods struct {
Name string
Price float64
}
type Brand struct {
Name string
Address string
}
type TV struct {
Goods
Brand
}
func main() {
//嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值
tv := TV{ Goods{"电视机001", 5000.99}, Brand{"海尔", "山东"}, }
tv2 := TV{
Goods{
Price : 5000.99,
Name : "电视机002",
},
Brand{
Name : "夏普",
Address :"北京",
},
}
} -
结构体的匿名字段可以是基本数据类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17type Monster struct {
Name string
Age int
}
type E struct {
Monster
int
n int
}
func main() {
var e E
e.Name = "狐狸精"
e.Age = 300
e.int = 20
e.n = 40
fmt.Println("e=", e)
}
多重继承:
- 如一个struct嵌套了多个匿名结构体,那么该结构体可以直接访问嵌套的匿名结构体的字段和方法,从而实现了多重继承
- 上上个例子中的TV,嵌套了Goods和Brand结构体
- 如嵌入的匿名结构体有相同的字段名或者方法名,则在访问时,需要通过匿名结构体类型名来区分
- 为了保证代码的简洁性,建议大家尽量不使用多重继承
4.接口
interface类型可以定义一组方法,但是这些不需要实现。并且 interface不能包含任何变量。到自定义类型(比如结构体 Phone)要使用的时候,在根据具体情况把这些方法写出来
基本语法:
1 | type 接口名 interface{ |
- 接口里的所有方法都没有方法体,即接口的方法都是没有实现的方法。接口体现了程序设计的多态和高内聚低偶合的思想
- Golang中的接口,不需要显式的实现。只要变量,含有接口类型中的所有方法,那变量就实现这个接口。因此, Galang中没有 implement这样的关键字
注意事项:
-
接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量(实例)
1
2
3
4
5
6
7
8
9
10
11func (stu Stu) Say() {
fmt.Println("Stu Say()")
}
type AInterface interface {
Say()
}
func main() {
var stu Stu //结构体变量,实现了 Say() 实现了 AInterface
var a AInterface = stu
a.Say()
} -
接口中所有的方法都没有方法体,即都是没有实现的方法。
-
在 Golang中,一个自定义类型需要将某个接口的所有方法都实现,我们才说这个自定义类型实现了该接口。
-
一个自定义类型只有实现了某个接口,才能将该自定义类型的实例(变量)赋给接囗类型
-
只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型
1
2
3
4
5
6
7
8
9
10
11
12type AInterface interface {
Say()
}
type integer int
func (i integer) Say() {
fmt.Println("integer Say i =" ,i )
}
func main() {
var i integer = 10
var b AInterface = i
b.Say() // integer Say i = 10
} -
一个自定义类型可以实现多个接口
-
Golang接口中不能有任何变量
-
一个接口(比如A接口)可以继承多个别的接口(比如B,C接口),这时如果要实现A接口,也必须将B、C接口的方法也全部实现,但是不能够有相同的接口
-
interface类型默认是一个指针(引用类型),如果没有对 interface初始化就使用,那么会输出nil
-
空接囗
interface{}没有任何方法,所以所有类型都实现了空接口,即可以将任何一个变量赋值给空接口
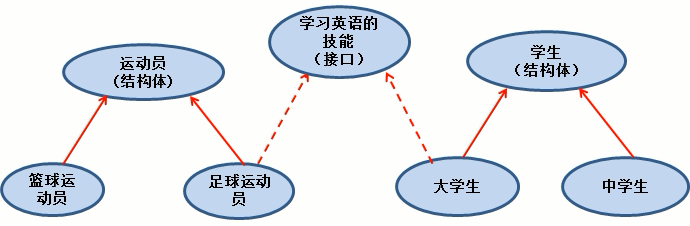
接口和继承的关系
-
接口是继承的补充
-
当A结构体继承了B结构体,那么A结构就自动的继承了B结构体的字段和方法,并且可以直接使用
-
当A结构体需要扩展功能,同时不希望去破坏继承关系,则可以去实现某个接口即可
-
接口和继承解决的问题不同
- 继承的价值主要在于:解决代码的复用性和可维护性
- 接口的价值主要在于:设计,设计好各种规范(方法),让其它自定义类型去实现这些方法
-
接口比继承更加灵活
- 继承是满足
is-a的关系,而接口只需满足like-a的关系。
- 继承是满足
-
接口在一定程度上实现代码解耦
5.多态
变量(实例)具有多种形态。面向对象的第三大特征,在Go语言,多态特征是通过接口实现的。可以按照统一的接口来调用不同的实现。这时接口变量就呈现不同的形态。
接口体现多态特性:
-
多态参数:在下面的Usb接口案例, Usb usb,即可以接收手机变量,又可以接收相机变量,就体现了Usb接口多态
-
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47//声明/定义一个接口
type Usb interface {
//声明了两个没有实现的方法
Start()
Stop()
}
type Phone struct {
}
//让Phone 实现 Usb接口的方法
func (p Phone) Start() {
fmt.Println("手机开始工作。。。")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作。。。")
}
type Camera struct {
}
//让Camera 实现 Usb接口的方法
func (c Camera) Start() {
fmt.Println("相机开始工作~~~。。。")
}
func (c Camera) Stop() {
fmt.Println("相机停止工作。。。")
}
//计算机
type Computer struct {
}
//编写一个方法Working 方法,接收一个Usb接口类型变量
//只要是实现了 Usb接口 (所谓实现Usb接口,就是指实现了 Usb接口声明所有方法)
func (c Computer) Working(usb Usb) {
//通过usb接口变量来调用Start和Stop方法
usb.Start()
usb.Stop()
}
func main() {
//先创建结构体变量
computer := Computer{}
phone := Phone{}
camera := Camera{}
//关键点
computer.Working(phone)
computer.Working(camera) //
}
-
-
多态数组:下面例子Usb数组中,存放 Phone结构体和 Camera结构体变量。Phone还有一个特有的方法call(),请遍历Usb数组,如果是 Phone变量,除了调用Usb接口声明的方法外,还需要调用 Phone特有方法call
-
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38//声明/定义一个接口
type Usb interface {
//声明了两个没有实现的方法
Start()
Stop()
}
type Phone struct {
name string
}
//让Phone 实现 Usb接口的方法
func (p Phone) Start() {
fmt.Println("手机开始工作。。。")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作。。。")
}
type Camera struct {
name string
}
//让Camera 实现 Usb接口的方法
func (c Camera) Start() {
fmt.Println("相机开始工作。。。")
}
func (c Camera) Stop() {
fmt.Println("相机停止工作。。。")
}
func main() {
//定义一个Usb接口数组,可以存放Phone和Camera的结构体变量
//这里就体现出多态数组
var usbArr [3]Usb
usbArr[0] = Phone{"vivo"}
usbArr[1] = Phone{"小米"}
usbArr[2] = Camera{"尼康"}
fmt.Println(usbArr)
}
-
类型断言
类型断言,由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型断言,如下:
1 | var t float32 |
在进行类型断言时,如果类型不匹配,就会报 panic因此进行类型断言时,要确保原来的空接口指向的就是断言的类型
带检测的类型断言:
1 | var x interface{} |
可以通过这种方法判断输入参数的类型:
1 | type Student struct { |
十二、文件操作
文件在程序中是以流的形式来操作的
- 流:数据在数据源(文件)和程序(内存)之间经历的路径
- 输入流:数据从数据源(文件)到程序(内存)的路径
- 输出流:数据从程序(内存)到数据源(文件)的路径
os.File封装所有文件相关操作,File是一个结构体。
打开文件
1 | func Open(name string) (file *File, err error) |
另外一种打开文件的方式:
1 | func OpenFile(name string, flag int, perm FileMode) (file *File, err error) |
OpenFile是一个更一般性的文件打开函数,大多数调用者都应用Open或Create代替本函数。它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件对象可用于I/O。如果出错,错误底层类型是*PathError。(一般用于文件写入时的打开函数)
关闭文件
1 | func (f *File) Close() error |
读取文件
-
带缓冲的读取:
- 采取
bufio.NewReader(file)新建缓存,缓存大小默认为4096
1
2
3
4//NewReader创建一个具有默认大小缓冲、从r读取的*Reader。
func NewReader(rd io.Reader) *Reader
//ReadString读取直到第一次遇到delim字节,返回一个包含已读取的数据和delim字节的字符串。如果ReadString方法在读取到delim之前遇到了错误,它会返回在错误之前读取的数据以及该错误(一般是io.EOF)。当且仅当ReadString方法返回的切片不以delim结尾时,会返回一个非nil的错误。
func (b *Reader) ReadString(delim byte) (line string, err error)例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26file , err := os.Open("d:/test.txt")
if err != nil {
fmt.Println("open file err=", err)
}
//当函数退出时,要及时的关闭file
defer file.Close() //要及时关闭file句柄,否则会有内存泄漏.
// 创建一个 *Reader ,是带缓冲的
/*
const (
defaultBufSize = 4096 //默认的缓冲区为4096
)
*/
reader := bufio.NewReader(file)
//循环的读取文件的内容
for {
str, err := reader.ReadString('\n') // 读到一个换行就结束
if err == io.EOF { // io.EOF表示文件的末尾
break
}
//输出内容
fmt.Printf(str)
}
fmt.Println("文件读取结束...") - 采取
-
一次性读取(适合文件不大的情况下,效率低)
-
利用函数
ioutil.ReadFile一次性读取(无需打开文件,直接读取)1
2
3
4
5
6
7
8
9
10
11
12//使用ioutil.ReadFile一次性将文件读取到位
file := "d:/test.txt"
content, err := ioutil.ReadFile(file)
if err != nil {
fmt.Printf("read file err=%v", err)
}
//把读取到的内容显示到终端
//fmt.Printf("%v", content) // []byte
fmt.Printf("%v", string(content)) // []byte
//我们没有显式的Open文件,因此也不需要显式的Close文件
//因为,文件的Open和Close被封装到 ReadFile 函数内部
-
写文件
通过缓存,即bufio中的bufio.NewWriter写文件
1 | //NewWriter创建一个具有默认大小缓冲、写入w的*Writer。 |
例子:
1 | //创建一个新文件,写入内容 5句 "hello, Gardon" |
通过ioutil.WriteFile写文件(无需打开文件,直接写入):
1 | func WriteFile(filename string, data []byte, perm os.FileMode) error |
函数向filename指定的文件中写入数据。如果文件不存在将按给出的权限创建文件,否则在写入数据之前清空文件。
判断文件是否存在
golang判断文件或文件夹是否存在的方法为使用 os.Stat()函数返回的错误值进行判断
- 1)如果返回的错误为nil,说明文件或文件夹存在
- 2)如果返回的错误类型使用 os.IsNotExist()判断为true,说明文件或文件夹不存在
- 3)如果返回的错误为其它类型则不确定是否在存在
1 | func Stat(name string) (fi FileInfo, err error) |
Stat返回一个描述name指定的文件对象的FileInfo。如果指定的文件对象是一个符号链接,返回的FileInfo描述该符号链接指向的文件的信息,本函数会尝试跳转该链接。如果出错,返回的错误值为*PathError类型。
文件拷贝
io包中的Copy函数:
1 | func Copy(dst Writer, src Reader) (written int64, err error) |
将src的数据拷贝到dst,直到在src上到达EOF或发生错误。返回拷贝的字节数和遇到的第一个错误。
对成功的调用,返回值err为nil而非EOF,因为Copy定义为从src读取直到EOF,它不会将读取到EOF视为应报告的错误。如果src实现了WriterTo接口,本函数会调用src.WriteTo(dst)进行拷贝;否则如果dst实现了ReaderFrom接口,本函数会调用dst.ReadFrom(src)进行拷贝。
注意:dst为Writer类型,src为Reader类型,需要NewWriter和NewReader函数进行创建
例子:
1 | func CopyFile(dstFileName string, srcFileName string) (written int64, err error) { |
命令行参数
os.Args是一Ar个 string的切片,用来存储所有的命令行参数
1 | fmt.Println("命令行的参数有", len(os.Args)) |
用flag包解析命令行参数:
1 | func (f *FlagSet) Int64(name string, value int64, usage string) *int64 |
Int64用指定的名称、默认值、使用信息注册一个int64类型flag。返回一个保存了该flag的值的指针。
1 | func (f *FlagSet) StringVar(p *string, name string, value string, usage string) |
StringVar用指定的名称、默认值、使用信息注册一个string类型flag,并将flag的值保存到p指向的变量。
1 | func Parse() |
从os.Args[1:]中解析注册的flag。必须在所有flag都注册好而未访问其值时执行。未注册却使用flag -help时,会返回ErrHelp。
例子:
1 | //定义几个变量,用于接收命令行的参数值 |
JSON
JSON易于机器解析和生成,并有效地提升网络传输效率,通常程序在网络传输时会先将数据(结构体、map等)序列化成json字符串,到接收方得到json字符串时,在反序列化恢复成原来的数据类型(结构体、map等)。这种方式已然成为各个语言的标准。
JSON键值对是用来保存数据一种方式,键/值对组合中的键名写在前面并用双引号""包裹,使用冒号:分隔,然后紧接着值
任何数据类型都可以转换成JSON格式(对基本数据类型(int、float64等)序列化一般意义不大)
https://www.json.cn/网站可以验证一个json格式的数据是否正确
序列化
encoding/json包中Marshal函数:
1 | func Marshal(v interface{}) ([]byte, error) |
返回v的json编码。
例子:
1 | //序列化Struct |
1 | //序列化Map |
1 | //序列化slice |
- 对于结构体的序列化,如果我们希望序列化后的key的名字,由我们自己重新制定,那么可以给 struct指定一个tag标签
反序列化
encoding/json包中Unmarshal函数:
1 | func Unmarshal(data []byte, v interface{}) error |
解析json编码的数据并将结果存入v指向的值
例子:
1 | //反序列化struct |
1 | //反序列化map |
1 | //反序列化slice |
- 在反序列化串时,要确保反序列化后的数据类型和原来序列化前的数据类型一致
- 如果json字符串是通过程序获取到的,则不需要再对json字符串转义处理
十三、单元测试
Go语言中自带有一个轻量级的测试框架 testing和自带的 go test命令来实现单元测试和性能测试, testing框架和其他语言中的测试框架类似,可以基于这个框架写针对相应函数的测试用例,也可以基于该框架写相应的压力测试用例。通过单元测试可以解决如下问题
- 1)确保每个函数是可运行,并且运行结果是正确的
- 2)确保写出来的代码性能是好的
- 3)单元测试能及时的发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决,而性能测试的重点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定
testing框架测试原理:

注意:
- 测试用例文件名_test.go结尾。比如 cal_test. go,cal不是固定的
- 测试用例函数必须以Test开头,一般来说就是Test+被测试的函数名,比如TestAddUpper
- 其中 Xxx 可以是任何字母数字字符串(但第一个字母不能是 [a-z]),用于识别测试例程
- TestAddUpper(t* tesing.T)的形参类型必须是
* testing.T【看一下手册】 - 测试用例文件中,可以有多个测试用例函数,如 TestAddUpper、 TestSub
- 运行测试用例指令
- (1)
cmd>go test【如果运行正确,无日志,错误时,会输出日志】 - (2)
cmd>go test -v【运行正确或是错误,都输出日志】
- (1)
- 当出现错误时,可以使用
t.Fatalf来格式化输出错误信息,并退出程序 t.Logf方法可以输出相应的日志- 测试用例函数,并没有放在main函数中,也执行了,这就是测试用例的方便之处
- PASS表示测试用例运行成功,FAIL表示测试用例运行失败
- 测试单个文件,一定要带上被测试的原文件:
go test -v cal_test.go(测试文件名) cal.go(测试文件所需要的函数)- 默认扫描整个目录下的所有测试文件
- 测试单个方法:
go test -v -test.run TestAddUpper(待测试的方法名)
十四、反射
基本介绍:
- 反射可以在运行时动态获取变量的各种信息,比如变量的类型(type),类别(kind),kind范围大于type
- 如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段、方法)
- 通过反射,可以使修改变量的值,可以调用关联的方法
- 使用反射需要
import ("reflect")
反射重要函数和概念:
reflect.Type(变量名),获取变量的类型,返回reflect.Type类型reflect.Valueof(变量名),获取变量的值,返回reflect.Value类型,reflect.Value是一结构体类型。通过reflect.Value,可以获取到关于该变量的很多信息- 变量、空接口
interface{}、reflect.Value是可以相互转换的
例子:
对基本数据类型、interface{}、reflect.Value进行反射
1 | func reflectTest01(b interface{}) { |
对结构体、interface{}、reflect.Value进行反射
1 | func reflectTest02(b interface{}) { |
注意事项和细节:
reflect.Value.Kind,获取变量的类别,返回的是一个常量- Type是类型,Kind是类别,Type和Kind可能是相同的,也可能是不同的
- 比如:var num int=10 num的Type是int,Kind也是int
- 比如:var stu Student stu的type是 包名.Student , Kind是 struct